In scientific computing tasks, both high-precision (hundreds to millions of bits) numerical data and low-precision data (deep neural networks introduced in AI for Science algorithms) need to be processed. We judge that supporting the emerging paradigm of future scientific computing requires a new architecture different from deep learning processors.
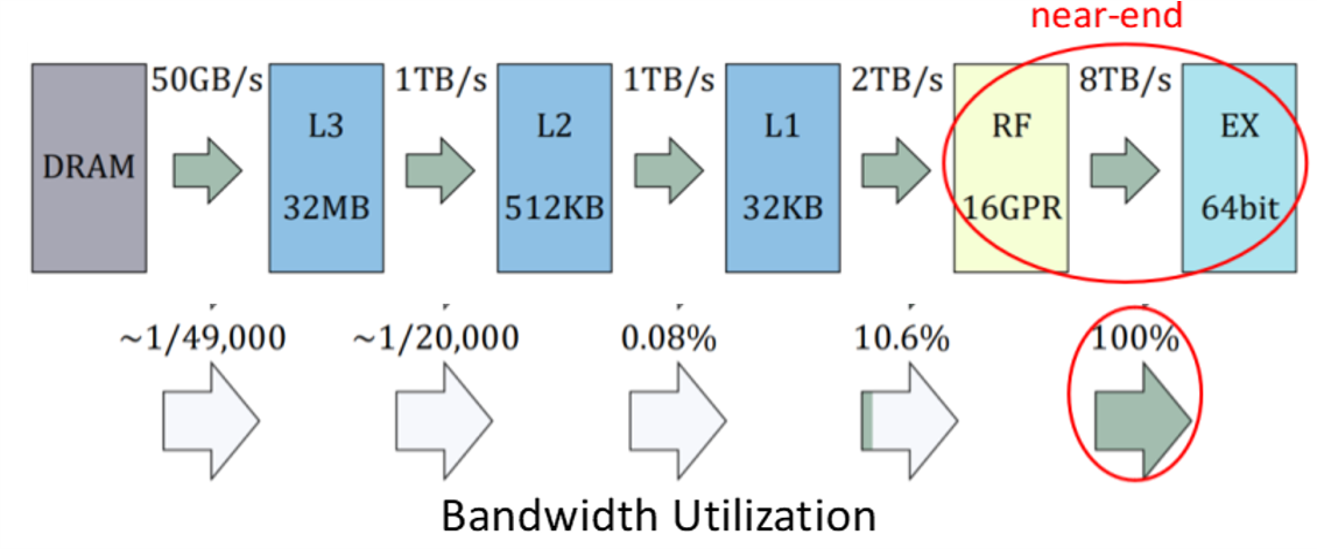
We analyzed the application characteristics of high-precision numerical computing and found that there is an “anti-memory wall” phenomenon: data transmission bottlenecks always appear at the near-computing storage hierarchy. This is because the data locality of numerical multiplication is so strong. If the word length natively supported by the computing device is not long enough, the operation needs to be decomposed into limbs, resulting in a huge amount of intermediate result memory access requests. Therefore, the new architecture must have: 1. The ability to process numerical multiplication; 2. The ability to process larger limbs at one time; 3. The ability to efficiently process large amounts of low-precision data.
Addressing these requirements, we designed the Cambricon-P architecture.
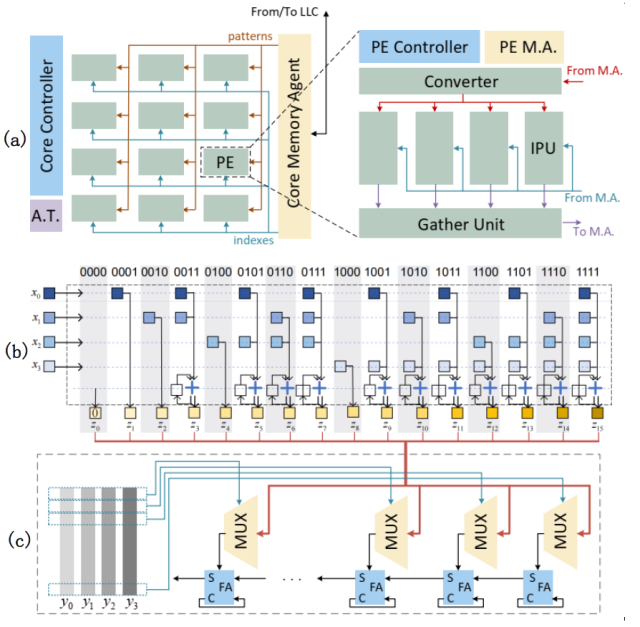
The Cambricon-P architecture has the following features:
- Use bitflow to support high-precision numerical multiplication and low-precision linear algebra operations at the same time;
- The carry-select mechanism alleviates the strong data dependence in the multiplication algorithm to a certain extent, and achieves sufficient hardware parallelism;
- Bit-indexed inner product algorithm decomposes the calculation process into single-bit vectors, exploits the redundant computing hidden in finite field linear algebra, and reduces the computing logic required to 36.7% of the trivial method.
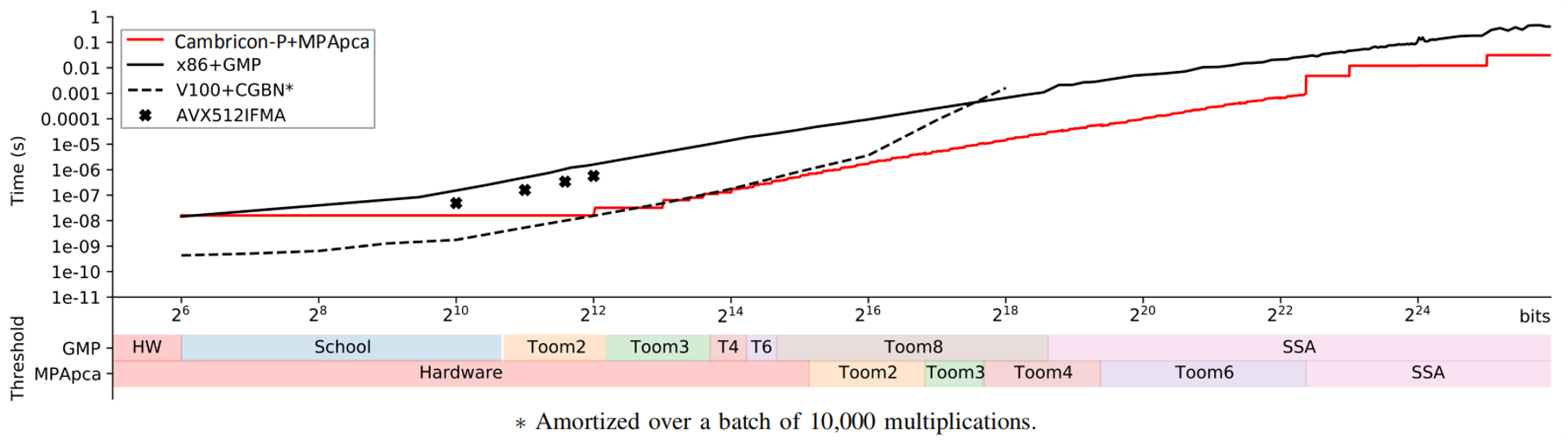
In order to achieve a larger-scale architecture and support larger limbs, the overall architecture of Cambricon-P is designed in a fractal manner, reusing the same control structure and similar data flows at the Core level, the Processing Element (PE) level, and the Inner Product Unit (IPU) level. We draftly developed the computing library MPApca for the Cambricon-P prototype, which implemented the Toom-Cook 2/3/4/6 fast multiplication algorithm and the Schönhage–Strassen fast multiplication algorithm (SSA) to evaluate against existing HPC systems such as CPU+GMP, GPU+CGBN.
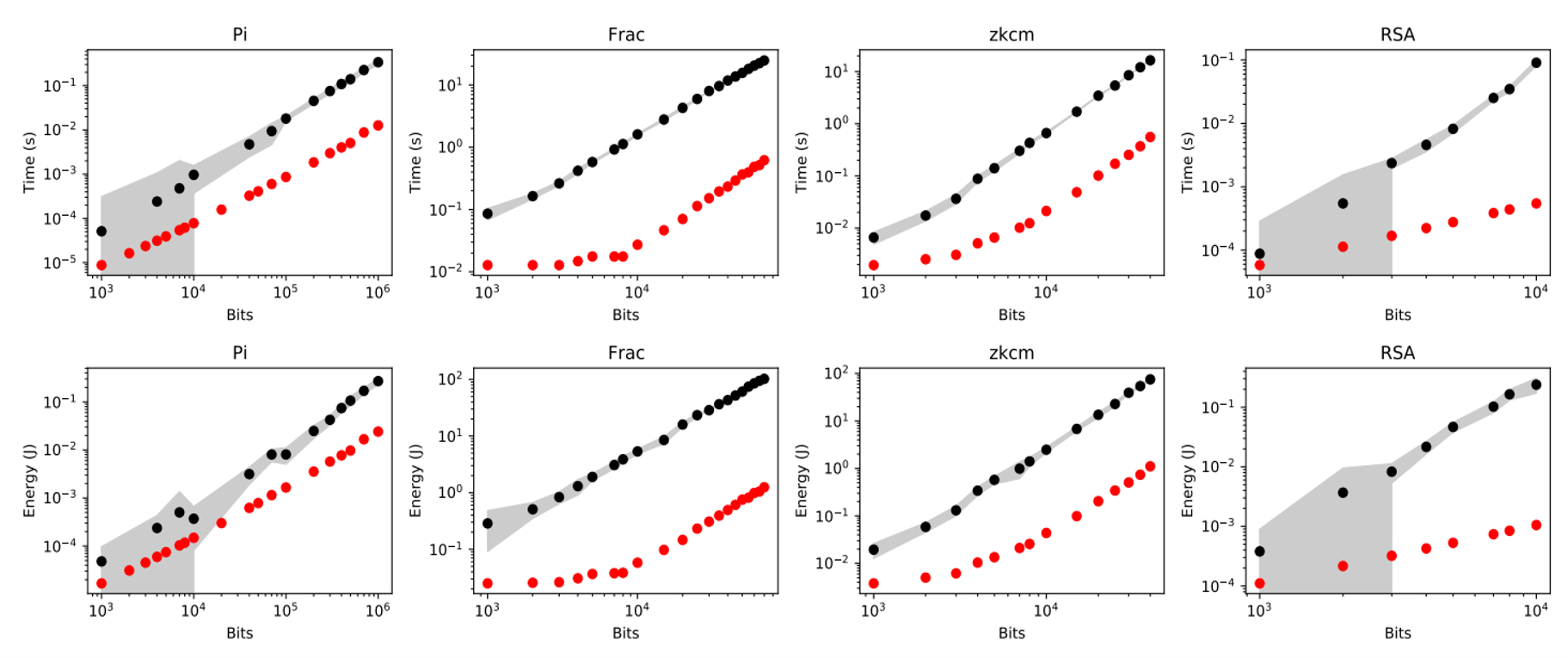
Experimental results show that MPApca achieves up to 100.98x speedup compared to GMP in a monolithic multiplication, and achieves on average 23.41x speedup, 30.16x energy efficiency improvement in four typical applications.
Published on MICRO 2022. [DOI] [PDF]
Since starting from 1968, there are 1,900+ papers accepted on MICRO. Cambricon-P is awarded as Best Paper Runner-up, resulting in as the 4th nominee from China mainland institutes.