In scientific computing tasks, both high-precision (hundreds to millions of bits) numerical data and low-precision data (deep neural networks introduced in AI for Science algorithms) need to be processed.
We judge that supporting the emerging paradigm of future scientific computing requires a new architecture different from deep learning processors.
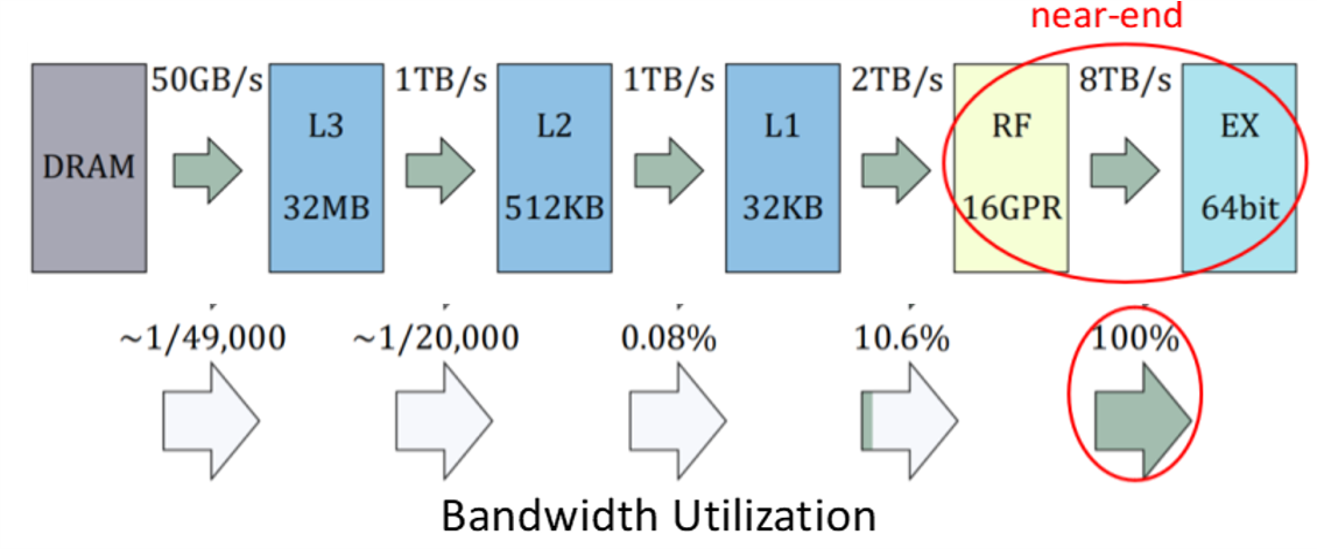
We analyzed the application characteristics of high-precision numerical computing and found that there is an “anti-memory wall” phenomenon: data transmission bottlenecks always appear at the near-computing storage hierarchy.
This is because the data locality of numerical multiplication is so strong. If the word length natively supported by the computing device is not long enough, the operation needs to be decomposed into limbs, resulting in a huge amount of intermediate result memory access requests.
Therefore, the new architecture must have: 1. The ability to process numerical multiplication; 2. The ability to process larger limbs at one time; 3. The ability to efficiently process large amounts of low-precision data.
Addressing these requirements, we designed the Cambricon-P architecture.
The Cambricon-P architecture has the following features:
Use bitflow to support high-precision numerical multiplication and low-precision linear algebra operations at the same time;
The carry-select mechanism alleviates the strong data dependence in the multiplication algorithm to a certain extent, and achieves sufficient hardware parallelism;
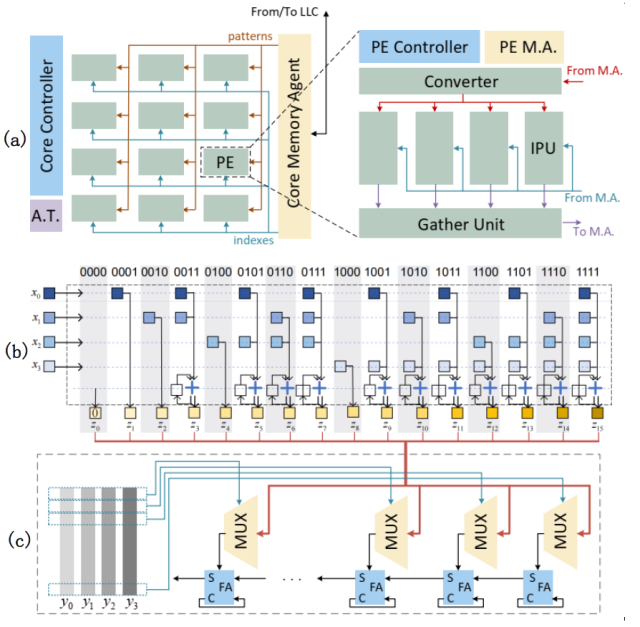
Bit-indexed inner product algorithm decomposes the calculation process into single-bit vectors, exploits the redundant computing hidden in finite field linear algebra, and reduces the computing logic required to 36.7% of the trivial method.
In order to achieve a larger-scale architecture and support larger limbs, the overall architecture of Cambricon-P is designed in a fractal manner, reusing the same control structure and similar data flows at the Core level, the Processing Element (PE) level, and the Inner Product Unit (IPU) level.
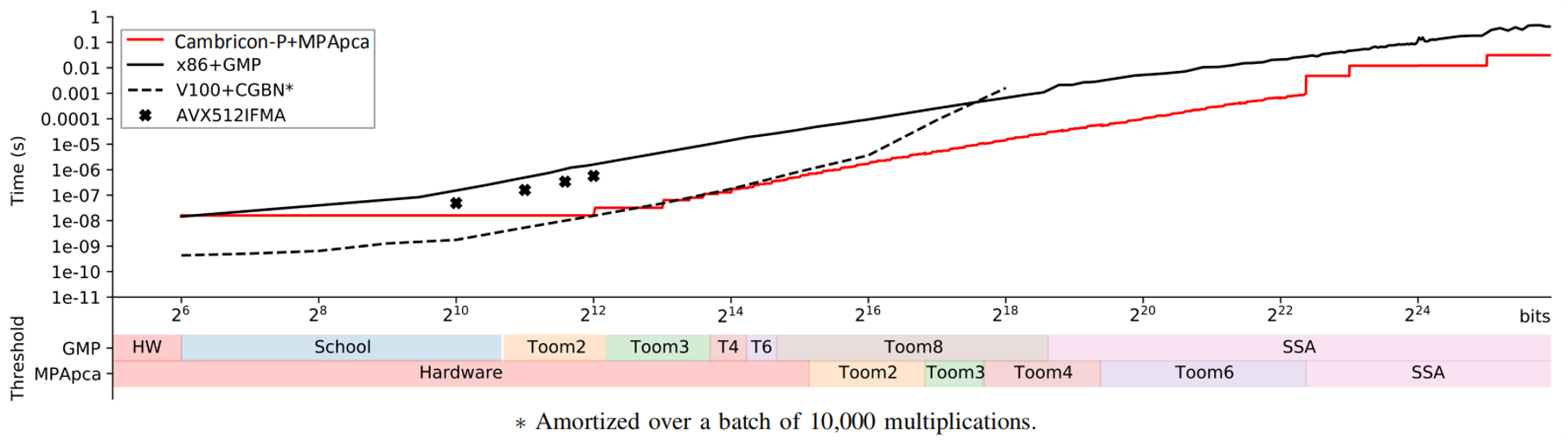
We draftly developed the computing library MPApca for the Cambricon-P prototype, which implemented the Toom-Cook 2/3/4/6 fast multiplication algorithm and the Schönhage–Strassen fast multiplication algorithm (SSA) to evaluate against existing HPC systems such as CPU+GMP, GPU+CGBN.
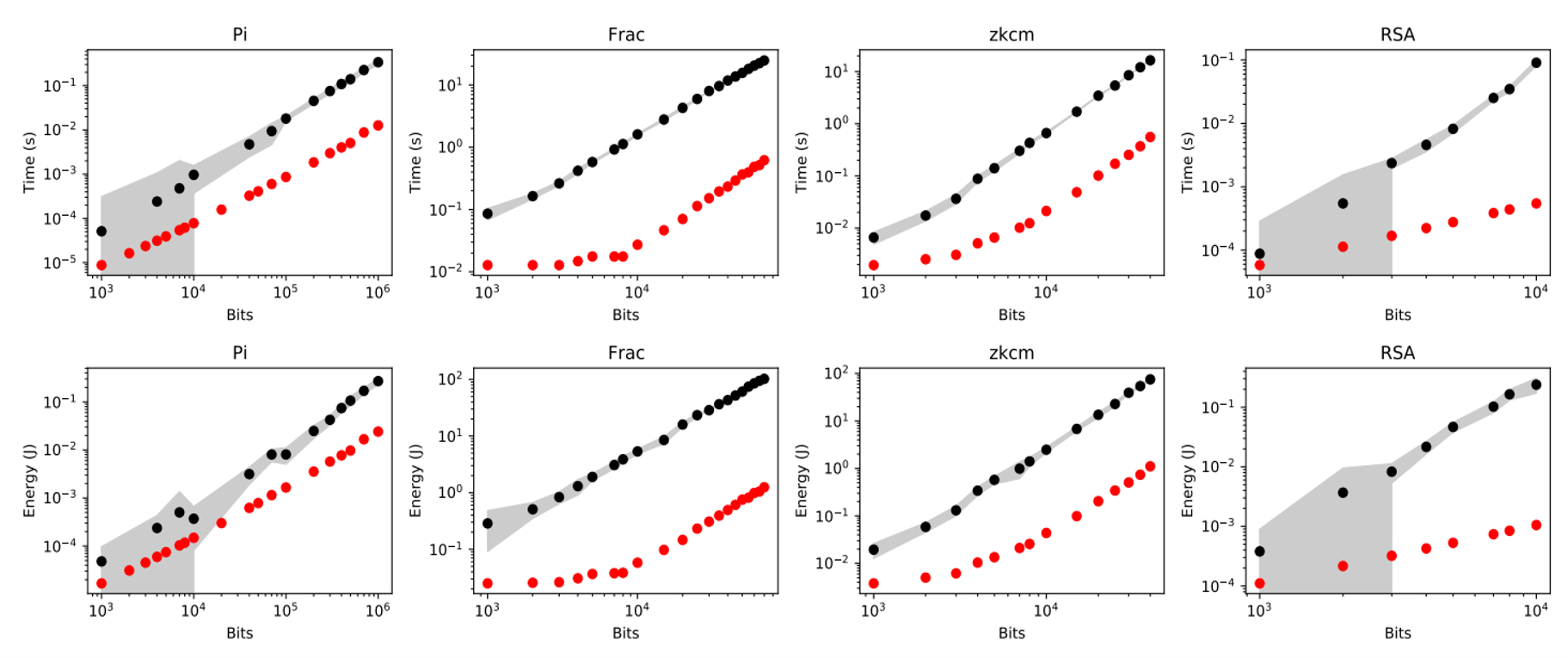
Experimental results show that MPApca achieves up to 100.98x speedup compared to GMP in a monolithic multiplication, and achieves on average 23.41x speedup, 30.16x energy efficiency improvement in four typical applications.
Since starting from 1968, there are 1,900+ papers accepted on MICRO. Cambricon-P is awarded as Best Paper Runner-up, resulting in as the 4th nominee from China mainland institutes.
Invited by Prof. LI, Chao of SJTU, I attended the 1st CCF Chips conference, and gave an online talk to the session of Outstanding Young Scholars in Computer Architecture.
In the talk I shared the results and extra thoughts from a paper under (single-blind) review, Rescue to the Curse of Universality.
Since the results are still undergoing peer review, the points are for reference only.
UPD: Paper published on SCIENCE CHINA: Informational Sciences. [DOI] [PDF]
Take home messages:
The Curse: It is impossible to build a computer that is both universal and efficient in logic circuits.
REnc Architecture: It is sufficient to be an efficient architecture that taking the locality as a scale-invariant constraint.
The results suggest that today’s DSAs may be over-specialized. There are theoretical rooms of universality while keeping the efficiency optimal.
With the laws from the semiconductor industry, we predict that DLPs are going to be more universal, more applicable, more standarized, and more systematic.
I have met JI, Yu, another CCF distinguished doctoral thesis award recipient, in Xining.
He is very confused about my doctoral thesis: How could you make such a complex system into fractals? You really did that at Cambricon?
I explained to him that fractalness is very primitive, rather than being made by me for thesis writing.
In the talkshow of the day, I redefined the concept of Fractal Parallel Computing: Fractalness (parallel computing) is the primitive property of parallel computed problems, that there exists a finite program to control the arbitrarily scaled parallel machines, and to solve the problem of any size in finite time.
It is not only Doctor JI. Many peers have raised similar concerns. Indeed, it is showing that my works are still very preliminary. I must admit that fractal machines are yet hardly useful in practice to any other developers.
But take an advice from me surely: if your system is not fractal, you should be really very cautious!
Allowing separate programming over a parallel machine can make the situation awkward:
The excessive programs serve as advice strings to the computation.
Take an MPMD model for example. Since I have nodes to program and work in parallel, I can hardcode one bit of information into each node. At the very begining of the computation, I can gather the bits, forming an -bit natural number and distribute it to all nodes. Let us denote that number as . Trivially, can represent values up to .
Why would that matters? is smuggled into the programs, which depends on the scale of the parallel machine, which is further scalable with the problem size , thus introduced non-uniformity. Say, we let indicate the number of Turing Machines of descriptive size that halt on empty tapes. Then we get the following algorithm immediately:
Input as the description of a TM ( bit).
Gather and distribute the value of .
.
Parallel-for each :
Simulate on an empty tape until halting.
Increase atomically.
If , abort the parallel for.
Return whether the -th simulation is finished or aborted.
It decides the Halting problem in finite time.
If your system does not allow that (deciding non-recursive problems), it is already fractal, although not necessarily in the identical form as in my thesis.
The fundamental problem is that, the excessive programs are harmful. Theoretically they cause the non-computable problems being computable on your system; Practically they raise various problems, including the rewriting every year problem we encountered in Cambricon (Cambricon-F: Machine Learning Computers with Fractal von Neumann Architecture). Fractal computing systems are against these bad practices.
When I was working on Cambricon-Q: A Hybrid Architecture for Efficient Training last year, I found that many graduate students do not know how to estimate errors, nor did they realize that error estimation is needed in randomized experiments. The computer architecture community does not pay enough attention to this. When performing experiments, our colleagues often run and measure a program of around ten milliseconds on the real system with the linux time command, and then report the speedup ratio compared with the simulation results. Such measurements are erroneous, and the results often fluctuate within a range; when the speedup is up to hundreds, a small measuring error may result in a completely different value in the final report. In elementary education, the experimental courses will teach us to “take the average of multiple measurements”, but how many times should “multiple times” be? Is 5 times enough? 10 times? 100 times? Or do you keep repeating it until the work is due? We need to understand the scientific method of experimentation: error estimation in repeated random experiments. I’ve found that not all undergraduate probability theory courses teach this, but it’s a must-have skill for a career in scientific research.
I am not a statistician, and I was also awful at courses when I was an undergraduate, so I am definitely not an expert in probability theory. But I used to delve into Monte Carlo simulation as a hobby, and I’m here to show how I did it myself. Statisticians, if there is a mistake, please correct me.
Gaussian Estimation
We have a set of samples , now assume that they are independent and identically distributed (i.i.d.), subject to a Gaussian distribution .
Although there is in the Gaussian distribution parameters, which is what we want, is not directly reflected in the measured samples. To approximate , we can take the arithmetic mean of the measured sample values. We first sum to get , then divide by . We get the arithmetic mean . Note that when a Gaussian random variable is divided by , the variance will be reduced by a factor of accordingly.
Although the above argument first assumes a Gaussian distribution, according to Levy-Lindeberg Central Limit Theorem (CLT), the infinite sum of any random variable tends to follow a Gaussian distribution, as long as those random variables satisfy the following two conditions:
Finite variances;
Independence.
So we can derive the distribution of directly from the CLT, no matter what distribution the samples actually follow, and the distribution is the same Gaussian.
As long as there are enough samples, will converges to .
The Gaussian distribution tells us that we are 99.7% confident that the difference between and the true value we want is no more than three times the standard deviation, i.e., . We say that the confidence interval for the 99.7% confidence level of estimated is .
As the number of experiments increases, the standard deviation of will continue to reduce. Originally we only knew that averaging over multiple measurements would work, and now we also know the rate of convergence: for every 4x more samples, the error will shrink by a factor of 2.
The constants 3 and 99.7% we use are a well known point on the Cumulative Distribution Function (CDF) of the Gaussian distribution, obtained by table look-up. Similar common values are 1.96 and 95%. To calculate the confidence level from the predetermined confidence interval, we use the CDF: , where the CDF only excludes the right-side tail, while the interval we estimate is two-sided, so the confidence level should subtract the left-side tail, i.e., . If you want to calculate the confidence interval from the target confidence level, you need to use the inverse function of CDF (ICDF), also known as PPF.
When programming, the CDF of the Gaussian distribution can be implemented relatively straightforward with the math library function erf. Its inverse function erfinv is not common, as it does not exist in the standard library of C or C++. However, CDF is continuous, monotonic, and derivable. Its derivative function is the Probability Density Function (PDF), so use numerical methods such as Newton’s method, secant, and bisection can all be applied for inversion efficiently.
However, the above estimation is entirely dependent on the CLT, which after all only describes a case in limits. In the actual experiment, we took 5 and 10 experimental results, which is far from the infinite number of experiments assumed. Do we still apply CLT though? This is obviously not scientific.
Student t-distribution
There is a more specialized probability distribution, the Student t-distribution, to define the sum of finitely many samples from random experiments. In addition to the above Gaussian estimation process, the t-distribution also considers the difference between the observed variance and the true variance .
The t-distribution is directly related to the degrees of freedom, which can be understood as in repeated random experiments. When the degrees of freedom are low, the tails of the t-distribution are longer, leading to a more conservative error estimate; as the degrees of freedom approach infinity, the t-distribution converges to a Gaussian distribution. For example, 5 samples, 4 degrees of freedom, and 99.7% confidence level, Gaussian estimated 3 times the standard deviation, while the t-distribution estimated 6.43 times, which is significantly enlarged.
When the number of trials is small, we use t-distribution instead of Gaussian distribution to describe . Especially when relying on error estimates to determine the early termination of repeated experiments, the use of Gaussian estimates is more prone to premature termination (especially when the first two or three samples happen to be similar).
Implementation
In Python, use packages: for Gaussian estimators use scipy.stats.norm.cdf and scipy.stats.norm.ppf, and for Student t-distribution estimators use scipy.stats.t.cdf and scipy.stats.t.ppf.
It is more difficult to implement in C++, the STL library is not fully functional for statistics, and it is inconvenient to introduce external libraries. The code below gives a C++ implementation of the two error estimators. The content between the two comment bars can be extracted as a header file for use, and the following part shows a sample program: Repeat experiments on until there is a 95% confidence that the true value will be included within plus or minus 10% of the estimated value.
/* error estimator for repeated randomized experiments. every scientists should know how to do this... requires c++17 or above. Copyright (c) 2021,2022 zhaoyongwei<zhaoyongwei@ict.ac.cn> IPRC, ICT CAS. Visit https://yongwei.site/error-estimator Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions: The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software. THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE. */
// ==================================================================== // contents before the DEMO rule is a header. // ==================================================================== // #pragma once // <-- don't forget opening this in a header. // compilers don't like this in the main file.
#define __STDCPP_WANT_MATH_SPEC_FUNCS__ 1 // for std::beta #include<cmath> #include<iterator> #include<tuple>
namespace errest {
// gaussian distribution. works as an approximation in most cases // due to CLT, but is over-optimistic, especially when samples are // few. template<classRealType =double> structgaussian { static RealType critical_score(RealType cl, size_t df){
// due to CLT, mean of samples approaches a normal distribution. // `erf` is used to estimate confidence level. // now we set a confidence level and try obtain corresponding // confidence interval, thus we need the inverse of `erf`, // i.e. `erfinv`. using std::log; using std::sqrt; using std::erf; using std::exp;
// solve erfinv by newton-raphson since c++stl lacks it. auto erfinv = [](RealType x) { constexpr RealType k = 0.88622692545275801; // 0.5 * sqrt(pi) RealType step, y = [](RealType x) { // a rough first approx. RealType sign = (x < 0) ? -1.0 : 1.0; x = (1 - x)*(1 + x); RealType lnx = log(x); RealType t1 = RealType(4.330746750799873)+lnx/2; RealType t2 = 1 / RealType(0.147) * lnx; return sign * sqrt(-t1 + sqrt(t1 * t1 - t2)); }(x); do { step = k * (erf(y) - x) / exp(-y * y); y -= step; } while (step); // converge until zero step. // this maybe too accurate for our usecase? // add a threshold or cache if too slow. return y; }; // we hope that the "truth" E[mean] lands in the interval // [mean-x*sigma, mean+x*sigma] with a probability of // conf_level = erf( x/sqrt(2) ) // conversely, // x = sqrt(2) * erfinv(conf_level) returnsqrt(RealType(2)) * erfinv(cl); // to get interval, mult this multiplier on the standard error of mean. } };
// student's t-distribution. yields an accurate estimation even for few // samples, but is more computational expensive. template<classRealType =double> structstudent { static RealType critical_score(RealType cl, size_t df){ // similar to gaussian, we need to evaluate ppf for critical score. // ppf is the inverse function of cdf, and pdf is the derivative // function of cdf. we find the inverse of cdf by newton-raphson. using std::beta; using std::sqrt; using std::pow; using std::lgamma; using std::exp; using std::log; using std::nextafter;
auto pdf = [](RealType x, RealType df) { returnpow(df / (df + x * x), (df + 1)/2) / (sqrt(df) * beta(df/2, RealType(0.5))); };
auto cdf = [](RealType x, RealType df) { // ibeta, derived from https://codeplea.com/incomplete-beta-function-c // original code is under zlib License, // Copyright (c) 2016, 2017 Lewis Van Winkle // i believe this snippet should be relicensed due to thorough rework. auto ibeta = [](RealType a, RealType b, RealType x){ const RealType lbeta_ab = lgamma(a)+lgamma(b)-lgamma(a+b); const RealType first = exp(log(x)*a+log(1-x)*b-lbeta_ab) / a; RealType f = 2, c = 2, d = 1, step; int m = 0; do { RealType o = -((a+m)*(a+b+m)*x)/((a+2*m)*(a+2*m+1)); m++; RealType e = (m*(b-m)*x)/((a+2*m-1)*(a+2*m)); RealType dt = 1 + o/d; d = 1 + e/dt; RealType ct = 1 + o/c; c = 1 + e/ct; f *= (step = (ct+e)/(dt+e)); } while(step - 1.); return first * (f - 1); }; RealType root = sqrt(x*x+df); returnibeta(df/2, df/2, (x + root)/(2*root)); };
cl = 1 - (1 - cl) / 2; // solve the root of cdf(x) - cl = 0. // first use newton-raphson, generally starting at 0 since cdf is // monotonically increasing. disallow overshoot. when overshoot // is detected, an inclusive interval is also determined, then // switch to bisection for the accurate root. RealType l = 0, r = 0, step; while((step = (cdf(r, df) - cl) / pdf(r, df)) < 0) { l = r; r -= step; } while (r > nextafter(l, r)) { RealType m = (l + r) / 2; (cdf(m, df) - cl < 0 ? l : r) = m; } returnnextafter(l, r); // let cdf(return val) >= 0 always holds. } };
// std::tie(mean, error) = estimator::test(first, last, cl) // // perform error estimation over the range [`first`, `last`). // the ground truth should be included in the interval // [`mean-error`, `mean+error`] with a probability of `cl`. template<class InputIt> static std::tuple<RealType,RealType> test (InputIt first, InputIt last, RealType cl = 0.95){
// sampling has 1 less degrees of freedom. auto n = distance(first, last); auto df = n - 1;
// pairwise sum to reduce rounding error. using std::distance; using std::next; using std::sqrt; auto sum = [](InputIt first, InputIt last, auto&& trans, auto&& sum)->RealType { if (distance(first, last) == 1) { returntrans(*first); } else { auto mid = first + distance(first, last) / 2; returnsum(first, mid, trans, sum) + sum(mid, last, trans, sum); } };
auto trans_mean = [n](RealType x)->RealType { return x/n; }; auto mean = sum(first, last, trans_mean, sum); auto trans_var = [mean, df](RealType x)->RealType { return (x - mean) * (x - mean) / df; }; auto var = sum(first, last, trans_var, sum);
// assuming samples are i.i.d., we estimate `mean` as // // samples[i] ~ N(mean, var) // sum = Sum(samples) // ~ N(n*mean, n*var) // mean = sum/n // ~ N(mean, var/n) // the standard error of mean, namely `sigma`, // sigma = sqrt(var/n). // // due to Levy-Lindeberg CLT, above estimation to `mean` // approximately holds for any sequences of random variables when // `m_iterations`->inf, as long as: // // * with finite variance // * independently distributed auto sigma = sqrt(var/n);
// finally, confidence interval is (+-) `critical_score*sigma`. // here critical_score is dependent on the assumed distribution. // we provide `gaussian` and `student` here. // // - `gaussian` works well for many (>30) samples due to CLT, // but are over-optimistic when samples are few; // - `student` is more conservative, depends on number of // samples, but is much more computational expensive. return { mean, Distribution<RealType>::critical_score(cl, df) * sigma }; } };
using gaussian_estimator = estimator<gaussian>; using student_estimator = estimator<student>;
};
// ==================================================================== // DEMO: experiment with RNG, try to obtain its expectation. // ==================================================================== #include<random> #include<vector> #include<iostream> #include<iomanip>
intmain(int argc, char** argv){
// the "truth" hides behind a normal distribution N(5,2). // after this demo converged, we expect the mean very close to 5. // we use student's t-distribution here, which works better for // small sets. // if you change the distribution to gaussian, you will likely // see an increased chance to fail the challenge. std::random_device rd; std::mt19937 gen(rd()); std::normal_distribution<double> dist{5,2}; // <-- the "truth"
while (1) { // draw 5 more samples then test. std::cout << "Single Experiment Results: "; for (size_t i = 0; i < iteration; i++) { double sample = dist(gen); // <-- perform a single experiment. samples.push_back(sample); if (i < 10) std::cout << sample << " "; elseif (i < 11) std::cout << "..."; } std::cout << std::endl;
// test the confidence interval with our estimator. std::tie(mean, error) = errest::student_estimator::test(samples.begin(), samples.end(), confidence_level); // or with structured binding declaration [c++17]: // auto [mean, error] = errest::student_estimator::test(samples.begin(), samples.end(), confidence_level);
Due to the emerging deep learning technology, deep learning tasks evolve toward complex control logic and frequent host-device interaction. However, the conventional CPU-centric heterogenous system has high host-device interaction overhead and slow improvement in interaction speed. Eventually, this leads to the problem of “interaction wall”, a gap between the improvement of interaction speed and the improvement of device computing speed. According to Amdahl’s law, this would severely limit the application of accelerators.
Addressing this problem, the CPULESS accelerator proposes a fused pipeline structure, which makes deep learning processor the center of the system, eliminating the need for an discrete host CPU chip. With the exception-oriented programming, the DLPU-centric system can combine the scalar control unit and the vector operation unit, and interaction overhead in between is minimized.
Experiments show that on a variety of emerging deep learning tasks with complex control logic, the CPULESS system can achieve 10.30x speedup and save 92.99% of the energy consumption compared to the conventional CPU-centric discrete GPU system.
Published in “IEEE Transactions on Computers”. [DOI] [PDF] [Artifact]
The pageview counter designed for this site, i.e., the one at the footer.
I estimate that 99% of people nowadays use Python when dealing with MNIST.
But this site promises not to use Python, thus chooses C++ for this gadget.
The overall experience is not much complicated than Python,
while it is expected to save a lot of carbons😁.
Implementation
Download MNIST testset and uncompress by gzip.
LeCun said that the first 5k images are easier, so the program only use the first 5k images.
Counter is saved into a file fcounter.db.
Digits are randomly chosen from test images, assembled into one PNG image,
(with Magick++ which is easier),
then returned to the webserver via FastCGI.
voidinit(){ t10k_labels.seekg(LABEL_IN); for (size_t i = 0; i < IMAGE_NUM; i++) { unsignedchar c; t10k_labels.read(reinterpret_cast<char*>(&c), 1); categories.insert({c, i * IMAGE_BYTE + IMAGE_IN}); } std::ifstream fcounter("./fcounter.db", std::ios_base::binary | std::ios_base::in); fcounter.read(reinterpret_cast<char*>(&count), sizeof(count)); fcounter.close(); }
voidselect(std::array<unsignedchar, IMAGE_BYTE>& img, unsignedchar c){ auto range = categories.equal_range(c); auto first = range.first; auto last = range.second; auto n = std::distance(first, last); std::uniform_int_distribution<> dist(0, n - 1); auto sk = std::next(first, dist(mt))->second; t10k_images.seekg(sk); t10k_images.read(reinterpret_cast<char*>(img.data()), IMAGE_BYTE); }
voidhit(std::ostream& os){ count++; std::ofstream fcounter("./fcounter.db", std::ios_base::binary | std::ios_base::out); fcounter.write(reinterpret_cast<char*>(&count), sizeof(count)); fcounter.close(); std::string str = std::to_string(count); if (str.length() < 6) str = std::string(6 - str.length(), '0') + str; size_t w = IMAGE_SIZE * str.length(), h = IMAGE_SIZE; std::vector<unsignedchar> canvas(w*h, 0); size_t i = 0; for (auto&& c : str) { std::array<unsignedchar, IMAGE_BYTE> img; select(img, c - '0'); for (int y = 0; y < IMAGE_SIZE; y++) { std::memcpy(&canvas[y * w + i * IMAGE_SIZE], &img[y * IMAGE_SIZE], IMAGE_SIZE); } i++; } Magick::Image image(IMAGE_SIZE*str.length(), IMAGE_SIZE, "I", Magick::CharPixel, canvas.data()); Magick::Blob blob; image.type(Magick::GrayscaleType); image.magick("PNG"); image.write(&blob); os << "Content-Type: image/png\r\n"; os << "Content-length: " << blob.length() << "\r\n\r\n"; os.write(reinterpret_cast<constchar*>(blob.data()), blob.length()) << std::flush; }
For FastCGI++, compiler flags -lfcgi++ -lfcgi are required.
CMake can found Magick++ automatically. Otherwise, append compiler flags from magick++-config.
Deployment
I use spawn-fcgi to spawn the compiled binary (set as a service in systemd).
Most webservers support FastCGI, a reverse proxy to the port set by spawn-fcgi completes the deployment.
I use Caddy:
1 2 3
reverse_proxy /counter.png localhost:21930 { transport fastcgi }
Add /counter.png to the footer HTML, then you see digits bump on refresh.
Go through internal links will not bump if the explorer cached the image.
In order to pursue energy efficiency,
most deep learning accelerators use 8-bit or even lower bit-width computing units,
especially on mobile platforms.
Such low-bit-width accelerators can meet the accuracy requirements of inference tasks
with special technical means,
but they cannot be used during training,
because the numerical sensitivity of the training process is much higher.
How to extend the architecture to enable efficient mobile training?
In response to this problem, we proposed Cambricon-Q.
Cambricon-Q has introduced three new modules:
SQU supports on-the-fly statistics and quantization;
QBC manages the mixed precision and data format for the on-chip buffers;
NDPO performs the weight update process at the near memory end.
The proposed architecture can support a variety of quantization-aware training algorithms.
Experiments show that Cambricon-Q achieves efficient training with negligible accuracy loss.
Cambricon-F obtains the programming scale-invariant property via fractal execution, alleviating the programming productivity issue of machine learning computers.
However, the fractal execution on this computer is by the hardware controller and only supports a few common basic operators (convolution, pooling, etc.).
Other functions need to be built on the sequence of these operators.
We have found that when a limited and fixed instruction set is used to support complex and variable application payloads, inefficiency will occur.
When supporting regular algorithms such as conventional CNNs, the machine can achieve optimal efficiency.
However, in complex and variable application scenarios, even if the application itself conforms to the definition of fractal operation, it will cause inefficiency phenomenon.
The inefficiency phenomenon is defined as a suboptimal computational or communication complexity when certain applications are executed on a fractal computer.
This paper uses TopK and 3DConv to illustrate the inefficiency phenomenon.
An intuitive example:
The user wants to execute the application Bayesian Network, which conforms to the definition of fractal operation and can be executed efficiently in a fractal manner;
But because there is no such “Bayesian” instruction in Cambricon-F, the application can only be decomposed into a series of basic operations and then executed serially.
If the instruction set can be expanded, and a BAYES fractal instruction is added, the fractal execution can be maintained until the leaf node is reached, which significantly improves the computational efficiency.
Based on this, we improved the architecture of Cambricon-F and proposed Cambricon-FR with a fractal reconfigurable instruction set structure.
Analytically, Cambricon-F is a Fractal Machine, while Cambricon-FR can be seen as a Universal Fractal Machine;
Cambricon-F can achieve optimal efficiency on a specific application payload, while Cambricon-FR can achieve optimal efficiency on complex and variable application payloads.
Published in “IEEE Transactions on Computers”. [DOI] [PDF]
During the work as a software architect in the Cambricon Tech,
I deeply realized the pain points of software engineering.
When I first took over in 2016, the core software was developed by me and WANG Yuqing, with 15,000 lines of code;
when I left in 2018, the development team increased to more than 60 people, with 720,000 lines of code.
From the perspective of lines, the complexity of software doubles every 5 months.
No matter how much manpower is added, the team is still under tremendous development pressure:
customer needs are urgent and need to be dealt with immediately;
New features need to be developed, the accumulated old code needs to be refactored;
the documentation has not yet been established; the tests have not yet been established…
I may not be a professional software architect, but who can guarantee that the future changes are foreseen from the very beginning?
Just imagine: the underlying hardware was single-core; it became multi-core a year later; then it became NUMA another year later.
With such a rapid evolution, how can the same software be able to keep up without undergoing thorough refactoring?
The key to the problem is that, the scale of the hardware has increased, so the level of abstraction that needs to be programmed and controlled is also increasing, making programming more complicated.
We define the problem as the programming scale-variance.
In order to solve this problem from engineering practices, we started the research, namely Cambricon-F.
Addressing the scale-variance of programming, it is necessary to introduce some kinds of scale invariants.
The invariant we found is fractal: the geometric fractals are self-similar on different scales.
We define the workload in a fractal manner, so does the hardware architecture. Both scale invariants can be zoomed freely until a scale that is compatible with each other is found.
Cambricon-F first proposed the Fractal von Neumann Architecture. The key features of this architecture are:
Sequential code, parallel execution adapted to the hardware scale automatically;
Programming Scale-invariance: hardware scale is not coded, therefore code transfers freely between different Cambricon-F instances;