在科学计算任务中,既需要处理高精度(数百至数百万比特)数值数据,也需要处理低精度数据(科学智能算法中引入的深度神经网络)。我们判断支撑未来科学计算新范式,需要一种不同于深度学习处理器的新体系结构。
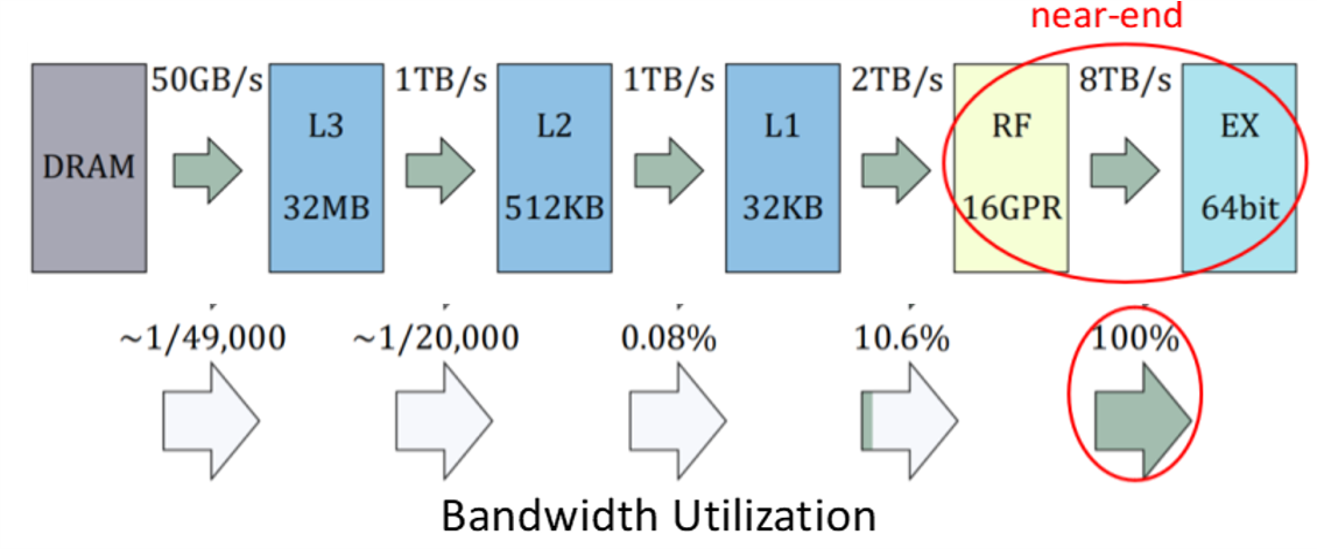
我们对高精度数值计算的应用特性进行分析,发现存在“反内存墙”现象:数据传输瓶颈总是出现在近端存储层次上。这是因为数值乘法的数据局部性极强,如果运算器件原生支持的字长不够长,就需要分解运算,产生巨额的中间结果访存请求。因此,新架构必须具有:1. 处理数值乘法的能力;2. 一次性处理更大字长的能力;3. 能够高效处理大量低精度数据。 针对这些需求,我们设计了Cambricon-P架构。
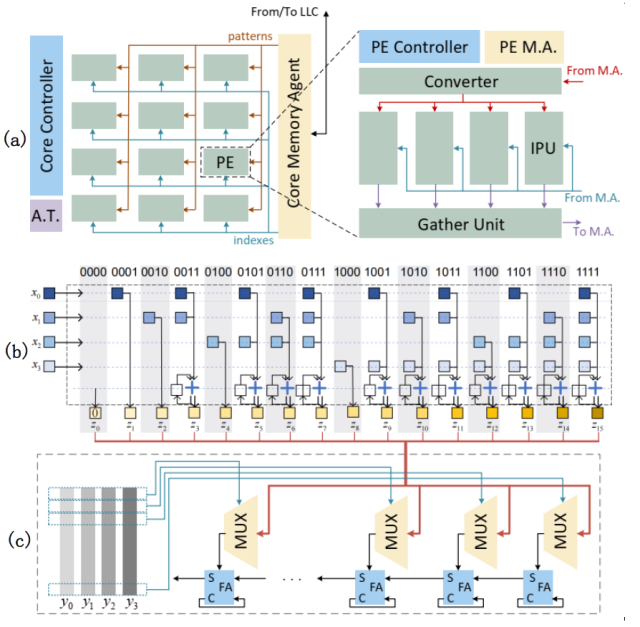
Cambricon-P架构具有以下特点:
- 采用逐位运算数据流,实现同时支持高精度数值乘法和低精度线性代数运算;
- 进位并行机制,一定程度上缓解乘法算法内的强数据依赖,实现充足的硬件并行性;
- 位索引内积计算算法,将计算过程分解至单比特向量,挖掘有限域线性代数中隐含的冗余计算,将计算逻辑降低至朴素方法的36.7%.
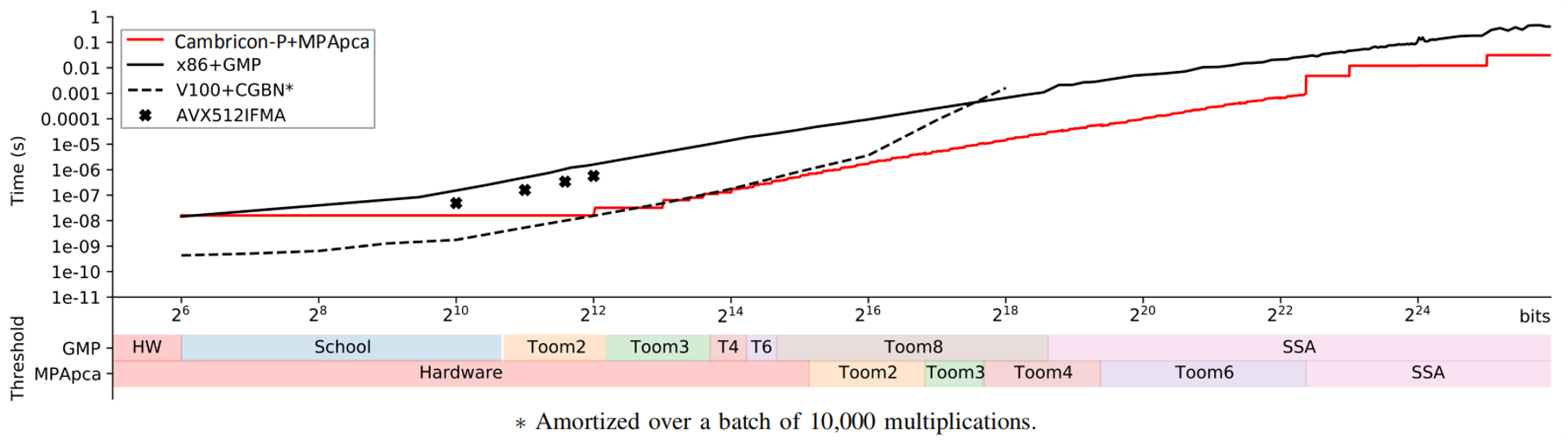
为实现更大规模架构支持更大字长,Cambricon-P整体架构采用分形方式设计,在核级、处理单元(PE)级、内积运算单元(IPU)级复用相同控制结构和相似的数据流。我们为Cambricon-P原型快速开发了配套运算库MPApca,实现了图姆-库克2/3/4/6快速乘法算法和颂哈吉-施特拉森快速乘法算法(SSA),以便与CPU+GMP、GPU+CGBN等现有高性能计算系统进行对比评估。
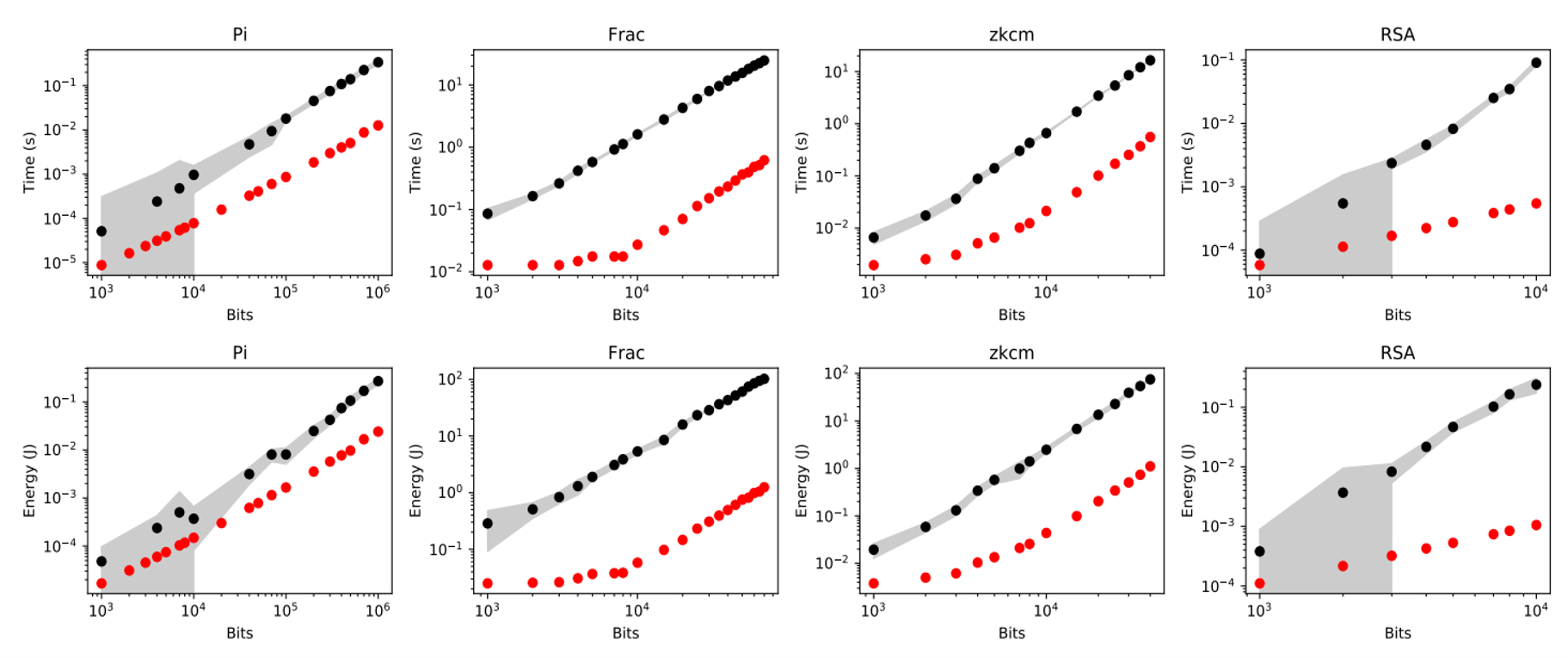
实验结果表明,Cambricon-P+MPApca在单个乘法运算时相比CPU+GMP最大加速达100.98倍,在四个典型应用上平均实现加速23.41倍、能效提升30.16倍。
自1968年创办以来,55届MICRO会议总共收录论文1900余篇。Cambricon-P获评大会最佳论文Runner-up奖,这是中国大陆研究团队第四次提名MICRO最佳论文。