我们关于硬连线LPU的论文已被计算机体系结构顶级会议 ASPLOS 2026 接收。在论文中,我们将大语言模型(LLM)直接硬连线制造于芯片电路结构之中,创造了一种全新的处理器形态“硬连线LPU”,其能效相比现有GPU实现了超过一千倍的提升。
在集成电路领域,将神经网络硬连线并不是新鲜事。自上世纪80年代起,这一构想就反复被提及,却因缺乏通用性而始终未能形成产业影响。以这些历史经验来套用未来,便形成了一种惯性智慧:“看,那些搞极端专用硬件的都失败了。英伟达之所以称霸,正是因为GPU处于通用性与效率的完美甜点(Sweet Spot)上。”
事实上,在现实世界中,“通用性”是一个工程经济学命题:它要求计算机创造的价值必须覆盖其工程成本,如不满足,那么这种新型计算机便不会存在。除此之外,没有任何物理铁律规定计算机硬件必须支持软件更新才能运转。试想,如果你突发奇想制造一台只能计算特定哈希函数的机器,这在教科书看来简直是离经叛道;但在现实中,只要合于利而动,不能更新又有何妨?多年后,那些思维开放、行动敏捷的人通过制造这种机器已经赚得盆满钵满,而旁观者只能在质疑中错失良机:“明天协议改成PoS了怎么办?你难道要再造一台吗?”
因此可知,一颗处理器的价值不在于它能支持多少种程序或更换多少代模型,而在于它是否找到了价值足够大的任务,哪怕只有一项。今天历史条件已悄然改变,人类获得了第一个值得被硬连线实现的神经网络——ChatGPT。现在,LLM所创造的应用价值已无需赘述,我们可以直观地量化:一台加密货币专用机每秒获得的收入不足一分钱;而按现行定价,一台硬连线LPU节点每秒创造的收入可达20元。
即使如此,也总有人会怀疑:“LLM迭代那么快,明天算法改成Mamba了怎么办?你难道要换硬件吗?”
为什么不呢?过去计算机强调软件更新,是因为软件迭代的边际成本几乎为零。但今天,训练一个具有竞争力的LLM所需的资本投入,已经历史性地超过了先进工艺芯片的改版费用。在这种条件下,更贵重的模型才是企业的核心资产,而芯片相对模型而言已是耗材。如果LLM的应用价值足以推动企业按季度甚至按月发布新模型,那么将一批定制处理器与旧模型一同淘汰,其经济损失是低微的。相比于丢弃芯片带来的只占小部头的额外成本,专用硬件带来的收益却是变革性的。一台硬连线LPU节点大约可替代由2000块H100构成的GPU集群。由于所需芯片数量大幅减少,数据中心的土建、运维、电力以及具形碳排放均可实现数百数千倍的节约。面对无序增长的推理需求,制造“月抛”型硬件、通过物理更换来实现模型更新,反而必将成为一种更经济、更环保的选择。
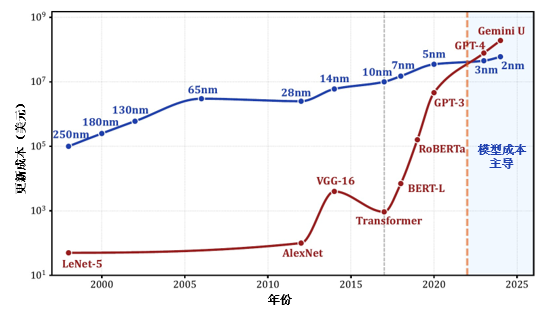
在我们看来,虽然技术上采用了最不可变动的方式来实现,但硬连线LPU仍是一种通用(General-purpose)处理器。它实现的是一般功用的LLM,因此硬件便自动连带获得了一般功用性;它在硬件层面直接实现对词元的处理,指令与数据都以提示词的形式输入来实现对通用问题的编程。它的软硬件界面(ISA)是自然语言,是无法被个别企业排他性使用的,也不再需要CUDA等软件的辅助,天然地消除了生态垄断的问题。它的计算能效可达到1 POPS/W量级,形成继CPU(标量,MOPS/W)、GPU(向量,GOPS/W)、NPU(矩阵,TOPS/W)之后的第四种通用处理器范式(词元,POPS/W)。
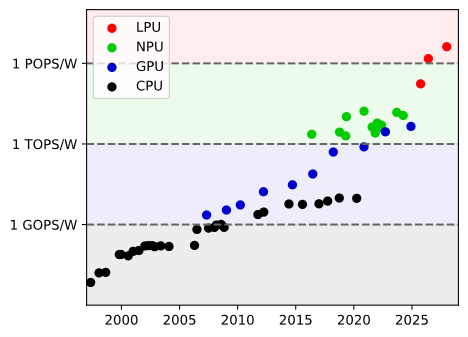
在有了原始构想之后,技术方案并不是短时间内就能简单取得的;对于同行而言,在完成整条路径的探索之前,这个构想听起来一直都过于不切实际。因此,自ChatGPT诞生以来不断地有人、有企业提出类似的想法、又很快全都放弃。据我们所知,UIUC、ARM、密歇根大学、东京大学在研究类似技术,均无法达到足以支持LLM的水平;初创公司Etched、Taalas等曾公开宣称要推出类似产品,迄今未获成功。我们的团队自2023年3月起开始研究能够实现硬连线LPU的合理技术方案,跨越算法、架构、工艺多个研究领域、有机结合了两项关键创新后才使预估成本降低至合理范围:
- 硬连线神经元架构(Hardwired-Neurons, HN):通过数学变换(团队称为原初化),将模型权重信息从二维平面的器件阵列中抽取出来,改由三维空间中的金属线网拓扑结构表达,每项权重都只需要编码成一根金属线的连接关系。这种方法在架构层设计中利用了通常只在物理设计过程中考虑的资源——芯片后道工艺中金属布线的垂直空间,实现了约15倍的编码密度提升。
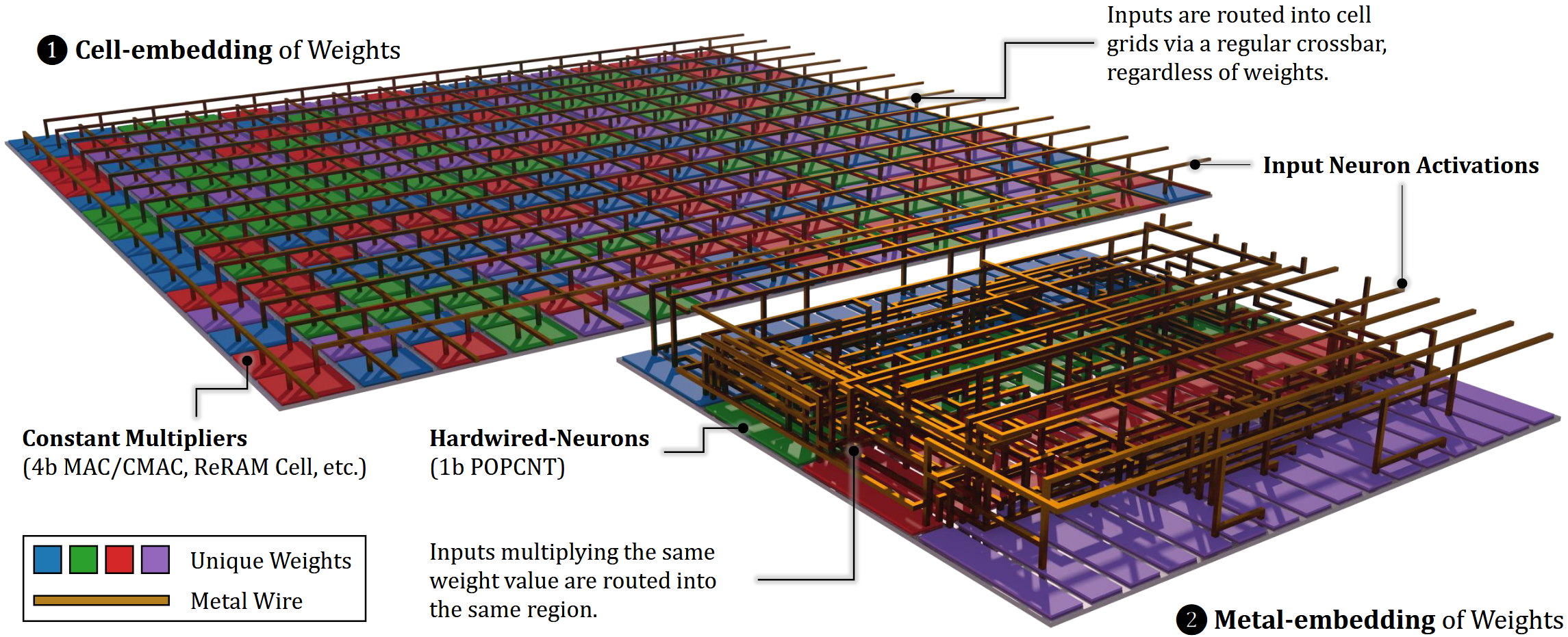
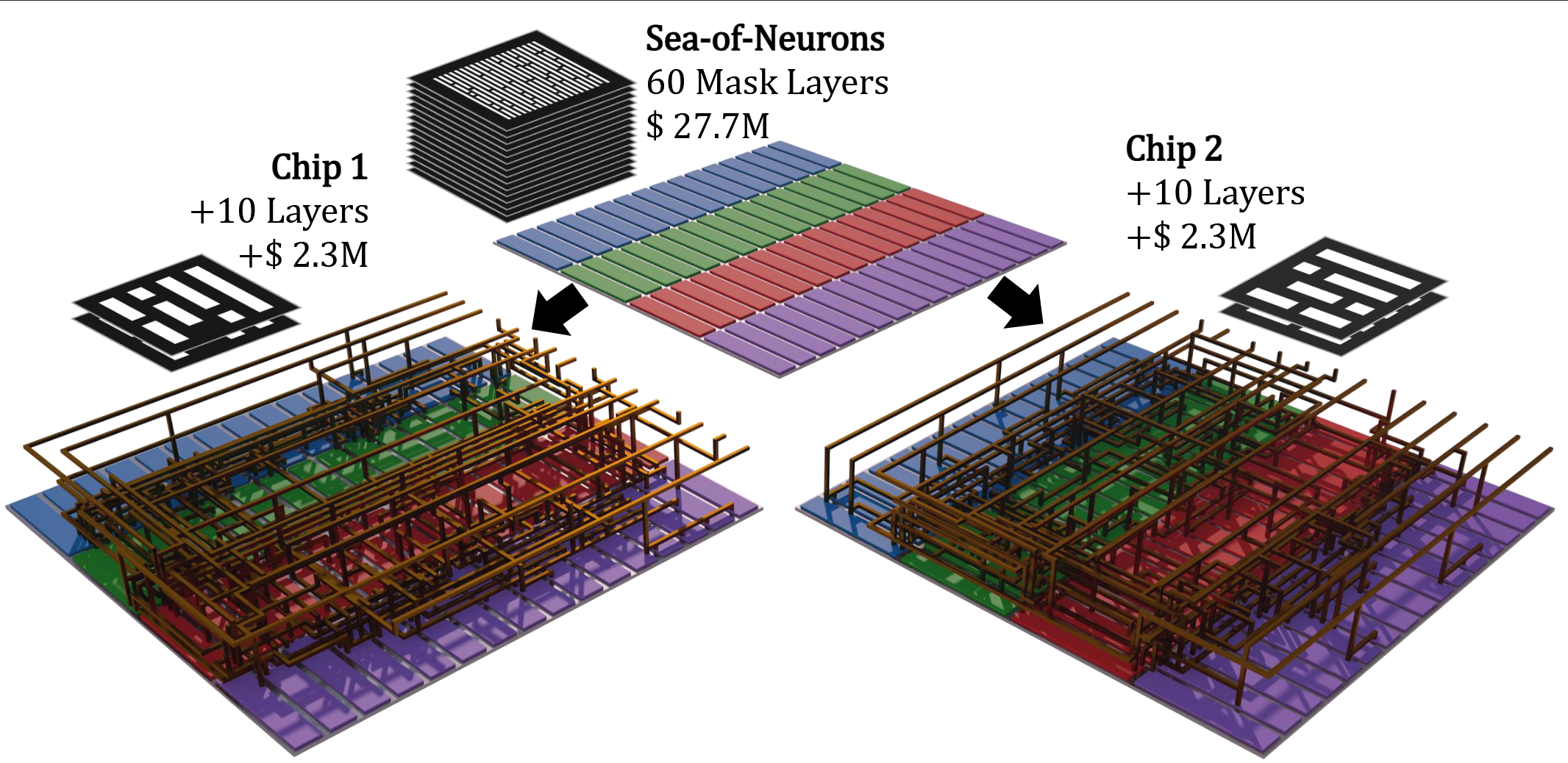
- 神经元海设计模式(Sea-of-Neurons, SoN):继HN将模型权重表达为金属线后,进一步将与模型权重相关的电路结构约束在仅M8-M11金属层中。这意味着每颗芯片所需的70层光罩中,有60层在不同模型间能够复用。SoN将首次流片和改版的光罩成本分别降低了86%和92%,使得为特定模型定制芯片在经济上更具吸引力。
学术原型系统“HNLPU”经过版图后仿真验证,在5 nm工艺、16×827 mm² 面积条件下,完整实现了OpenAI开源模型GPT-OSS 120B,保持了该模型原生采用的FP4数值格式精度。在单卡对比中,其性能、能效分别达到了英伟达H100的5555倍和1047倍;在每年更新一次硬件的大规模部署场景下,HNLPU相比GPU集群,运营成本、总成本、碳排放总量优势分别可达1496倍、41.7倍和357.2倍。
硬连线LPU是这样的一种处理器范式:它具备通用的、可编程的器件(用于计算注意力、位置编码、激活、采样等),具备一套用于存储键值序列的存储层次结构,具有横跨多芯片的高速互联系统,以及一个巨大的常值矩阵运算部件(HN阵列)。HN阵列的共有结构在上游企业预制,在下游企业确定LLM模型权重并下订后,再完成金属化将权重写入,快速而低廉地生产出搭载各个模型的超高效能芯片。我们预计这种新产业模式将取代GPU在长期、大规模推理部署市场的垄断地位,但同时也需要模型企业、芯片设计企业与芯片制造供应链之间进行尽可能强的深度整合。虽然还面临许多挑战,但历史上曾在芯片产业占据一席之地的结构化ASIC和门阵列(英特尔至今仍经营着eASIC业务),证明了这条路原本是可行的。
今年,我们预计将继续发布微调架构方案以及新的版图设计方案,实现低成本的模型容错和热修补,并将更换模型的改版成本再次降低十倍以上。同时,我们也在积极推进概念验证原型系统的试制。在国家重点研发计划的支持下,我们正在以国产工艺制作基于HN结构的硬连线人机交互处理器芯片,预计将实现不低于 1.5 POPS/W @ FP4 的计算能效。该芯片有望成为世界上计算能效最高的标准CMOS数字逻辑芯片。
敬请各位同仁关注我们的最新进展。
(本文部分内容截取自《硬连线LPU:大语言模型时代的处理器芯片新范式》初稿,原作者为:赵永威、郝一帆、刘洋、陈亦、陈云霁)