Taalas HC1最近引发广泛关注。本文尝试从技术角度解读它的架构,供同行参考。分析依据来自Taalas已公开的专利和访谈。由于其架构并未公开,许多细节需要基于反推猜测,不能保证准确。
HC1在架构上有两大进步:
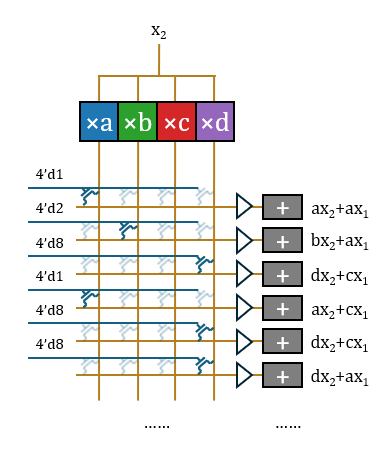
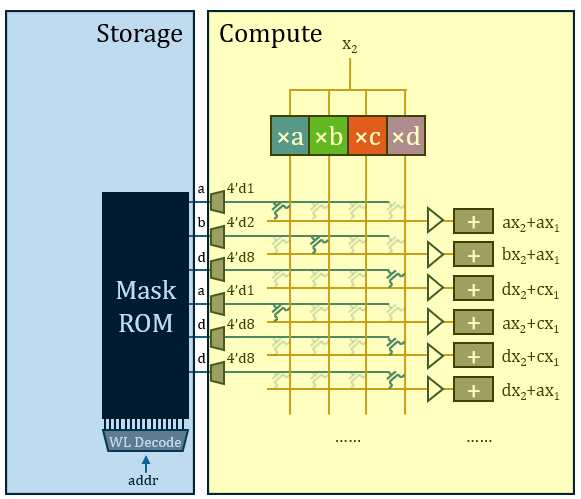
- 将朴素的矩阵运算器升级为专门适用于量化运算的机制,消除冗余计算,计算机制可概括为“乘-选-加”(而非朴素的“乘-加”);
- 采用了ROM为模型权值的存储介质,密度很高,修改模型权值时也只需要变更两张高层通孔掩模版。
新运算机制提升效率利用的是量化效应,而与固定权值带来的常值性无关。因此,HC1架构中存、算之间仍有十分清晰的边界。这意味着HC1运算过程中访存这一动作尚在,只是访问对象发生了改变。从密度而言,该方案已经很优秀;然而,目前的运算机制尚未完全利用权重的常值性,能效层面仍具备进一步挖掘的空间;其权值需要逐行从ROM中读出,限制了峰值性能表现。
在线性代数的语境中,每一个实数量都可以连续取值;但在计算机中数值的精度却总是有限的。特别是在对模型进行量化压缩后,量化效应更为凸显。例如,如果将权重矩阵内的每个量都量化到2-bit表示,无论数制如何设计,每个数最多只能取4种不同的值。在二进制整数数制下,这4种取值是0、1、2、3;这四个具体的值可以任意设计,形成二进制以外其他的数制来帮助更准确地量化,但最多只有四种,这是由两比特的信息容量所限制的。因此本文不失一般性地假设取值为
输入的神经元激活值要与这样一个权重矩阵相乘时,由于运算的次数已经超过了取值种类,运算就不可避免地产生了大量的重复。例如,假设权重矩阵的第一列是
对于如何消除这种反复来节约硬件开销,学界给出过多种不同的解法。Taalas采取的策略是LUT方案,即通过预计算-选择消除重复乘。由于量化后权重取值空间极小,输入激活值与所有可能权重取值的乘积可预先全部进行一次,列出所有可能用到的积,后续每一次单独的乘法运算都可以改为从预计算结果中选取现成的值。梳理Taalas已公开的14项专利,其核心机制主要记载于《Large parameter set computation accelerator…》(US20250123802A1)中。
1.乘:首先进行预计算,将
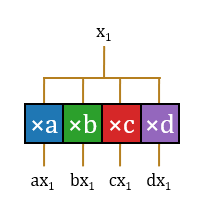
2.选:这样,
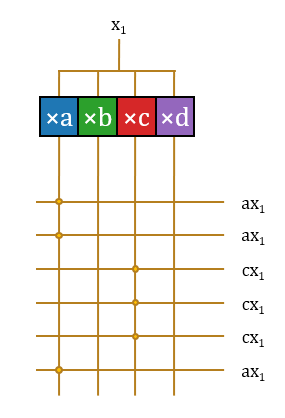
3.加:至此,该结构无重复地完成了这16项运算。这些运算分属16项不同的输出神经元激活值,因此需要16个不同的累加器累积起来。
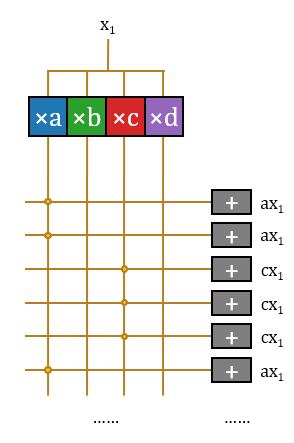
这样该结构完成了一个输入标量
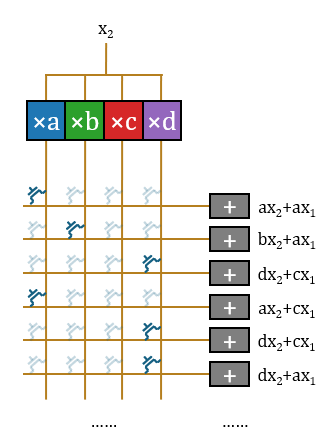
通常PTL构造传输门需要一对晶体管,但此处采用单个晶体管是合理的。单个晶体管只是会产生阈值电压降,在交叉开关阵列外、累加器前增加Buf恢复信号即可。Bajic声称公司手工绘制了一部分版图,很可能是用于处理这一部分。
晶体管的栅极需要提供独热控制向量,可以直接从ROM中读出。这样,完整的矩阵运算架构基本上已经形成。周围搭配词表查找表、随机采样、归一化、softmax、位置编码、激活函数这些辅助功能,配一个中等容量的SRAM用于存放KV(模型本身上下文很短),整个模型便完整实现了。
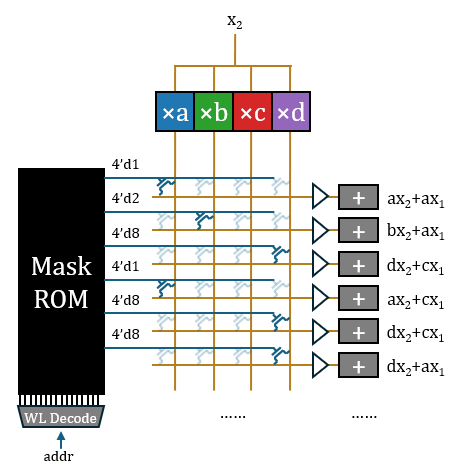
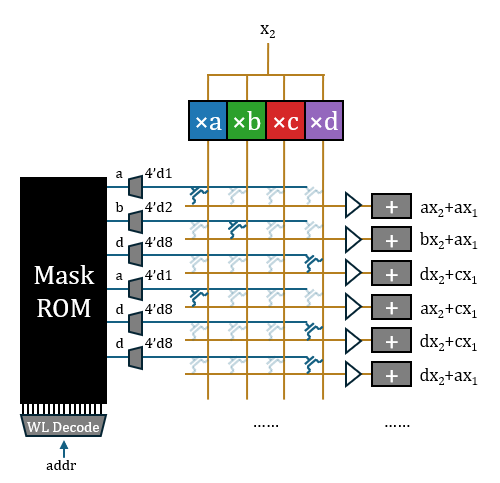
每个2比特权值转为4比特独热编码写入ROM,需要的ROM容量比较大,且不符合“store four bits away”的说法(HC1声称采用了3/6比特混合量化,如果是独热表示,至少应该“store eight bits”)。所以我认为ROM中烧录的应该是权重原值,然后通过3-8译码器转换为独热。译码器是矩阵外边的一维结构,总开销并不大。
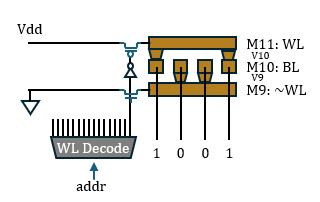
Taalas宣称定制Mask ROM需要变化两层光掩模。这很可能是用于两层Via通孔,其结构应当如图所示:受字线控制的VDD与GND互补地布满上下两层Trench,中间Trench作为读出的位线,以Via互补地在位线的上方或下方打孔来表示0或1。
所以,Taalas方案中真正硬连线的部分只有ROM的通孔。整个架构仍可以明确地分为存储部分与运算部分,存算在结构上是分离的。它没有消除广义上的访存,只是将访存对象的介质由SRAM(Groq)、HBM(Nvidia)变为ROM,访问读取的数据也极有可能是未经处理的权值原值。如果认为访问同一芯片上的存储器不算访存,那么消除这种狭义的“片外访存”的目标其实Groq方案就已经做到了。
运算部分是一个经典的量化运算架构,与UNPU、Cambricon-P等非常相似。运用这些架构改善量化矩阵乘法效率并不需要假设权值是固定的。我放一张架构图对比供参考。
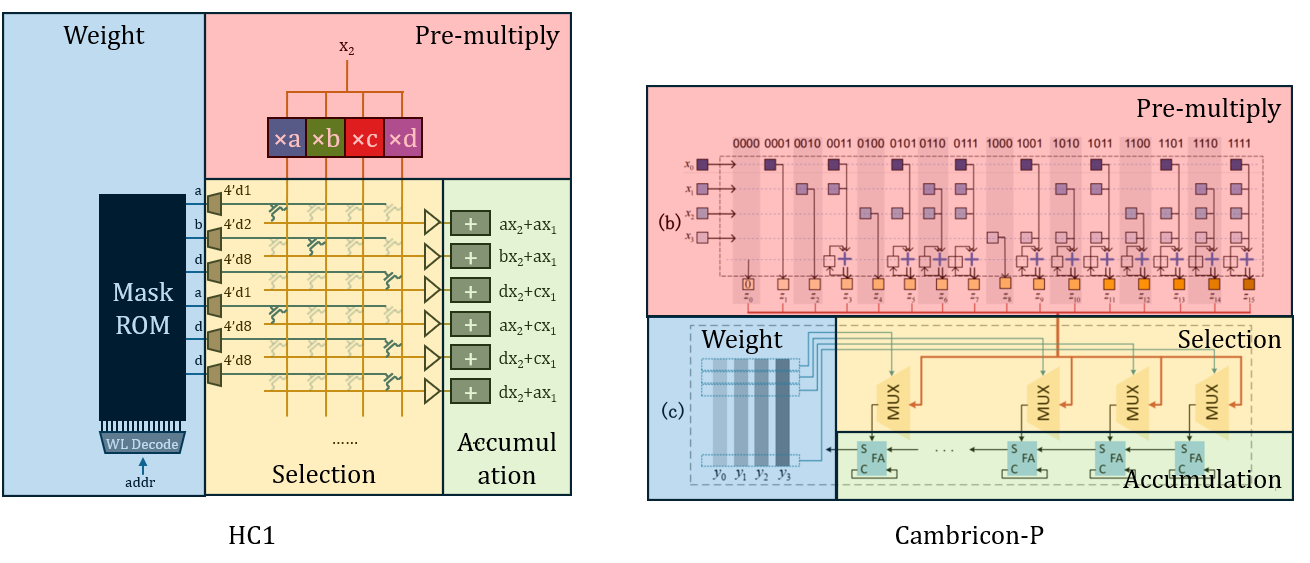
在此架构下,因为预乘法、累加、解码器、Buf这些结构都处于阵列外围,都是一维结构,所以都可以视作真正运算的准备工作或收尾工作,仅将二维的交叉开关视为真正的运算。在这种视角下,“一个晶体管完成所有运算”的说法也有一定的道理,只是略显夸大。从更严格的视角来看,它只承担了运算中的选通功能。
运算部分也可以直接用于处理变值矩阵,只要将交叉开关阵列控制信号来源由ROM切换到SRAM即可。猜测HC1就是这样支持LoRA的。这个架构可以通过调节尺寸参数,对运算器件(主要受限于晶体管元件)与存储器件(主要受限于高层金属通孔)进行面积平衡;但运算是需要通过逐行读取ROM完成的,所以一个矩阵完整处理完需要将整个ROM的所有地址遍历一遍,限制了峰值算力;如果将多个矩阵写入同一个ROM,这个架构就很难做流水并行。
密度上,由于运算和ROM存储是分离开的,比例可以随意调整,所以面积主要受限于ROM。假设ROM编码所用通孔的Half Pitch是62 nm,ROM bit-cell密度是0.015 μm²,8B平均4.0bpw的模型需要480 mm²,与实现基本吻合;如果降低几层到38 nm,密度0.0058 μm²,模型只需要约180 mm²,但无法单次曝光完成,模型更新成本会因此翻倍。由于硬连线芯片通常不需要特大规模量产,如果能与工艺配合,在产线中引入电子束光刻实现无掩膜通孔加工,有助于低成本实现高密度可变通孔;试想为芯片更换模型不再需要重新设计,只引入一两层每片成本几千元的电子束打孔工序就能源源不断流出搭载各种模型的芯片,硬连线语言处理器离落地的最后一点成本障碍就解决了。
单纯从架构设计角度而言,HC1还有许多地方值得商榷,但它真实实现了一个当下多数人尚不能接受的愿景。它本身只是一个Proof of Concept,对它的评价不应过于注重它当前表现出的智能能力。这个团队的思想已经早早转变过来,也已证明找到一条行之有效的技术路径,之后通往实现颠覆性产品的过程中还剩下的障碍已经不多了。最新前沿模型的硬连线芯片很快就会被实现,届时将对现有的AI计算范式与芯片产业格局产生深远影响。