If you prefer reading in English, there is a magical switch on the top-right corner.
本网站没有使用Python。
If you prefer reading in English, there is a magical switch on the top-right corner.
本网站没有使用Python。
Taalas HC1最近引发广泛关注。本文尝试从技术角度解读它的架构,供同行参考。分析依据来自Taalas已公开的专利和访谈。由于其架构并未公开,许多细节需要基于反推猜测,不能保证准确。
HC1在架构上有两大进步:
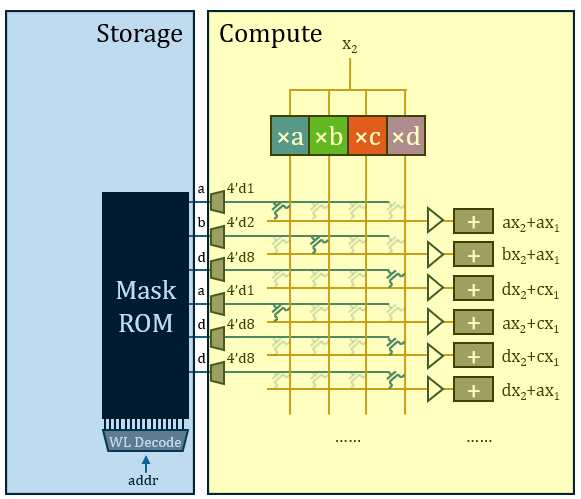
新运算机制提升效率利用的是量化效应,而与固定权值带来的常值性无关。因此,HC1架构中存、算之间仍有十分清晰的边界。这意味着HC1运算过程中访存这一动作尚在,只是访问对象发生了改变。从密度而言,该方案已经很优秀;然而,目前的运算机制尚未完全利用权重的常值性,能效层面仍具备进一步挖掘的空间;其权值需要逐行从ROM中读出,限制了峰值性能表现。
在线性代数的语境中,每一个实数量都可以连续取值;但在计算机中数值的精度却总是有限的。特别是在对模型进行量化压缩后,量化效应更为凸显。例如,如果将权重矩阵内的每个量都量化到2-bit表示,无论数制如何设计,每个数最多只能取4种不同的值。在二进制整数数制下,这4种取值是0、1、2、3;这四个具体的值可以任意设计,形成二进制以外其他的数制来帮助更准确地量化,但最多只有四种,这是由两比特的信息容量所限制的。因此本文不失一般性地假设取值为
输入的神经元激活值要与这样一个权重矩阵相乘时,由于运算的次数已经超过了取值种类,运算就不可避免地产生了大量的重复。例如,假设权重矩阵的第一列是
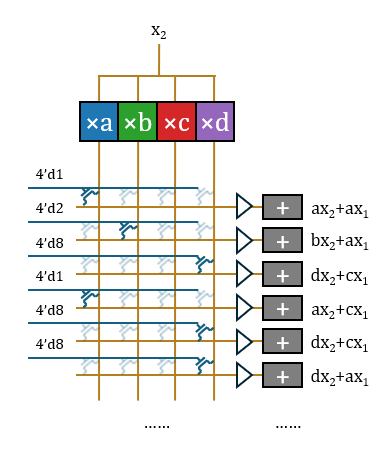
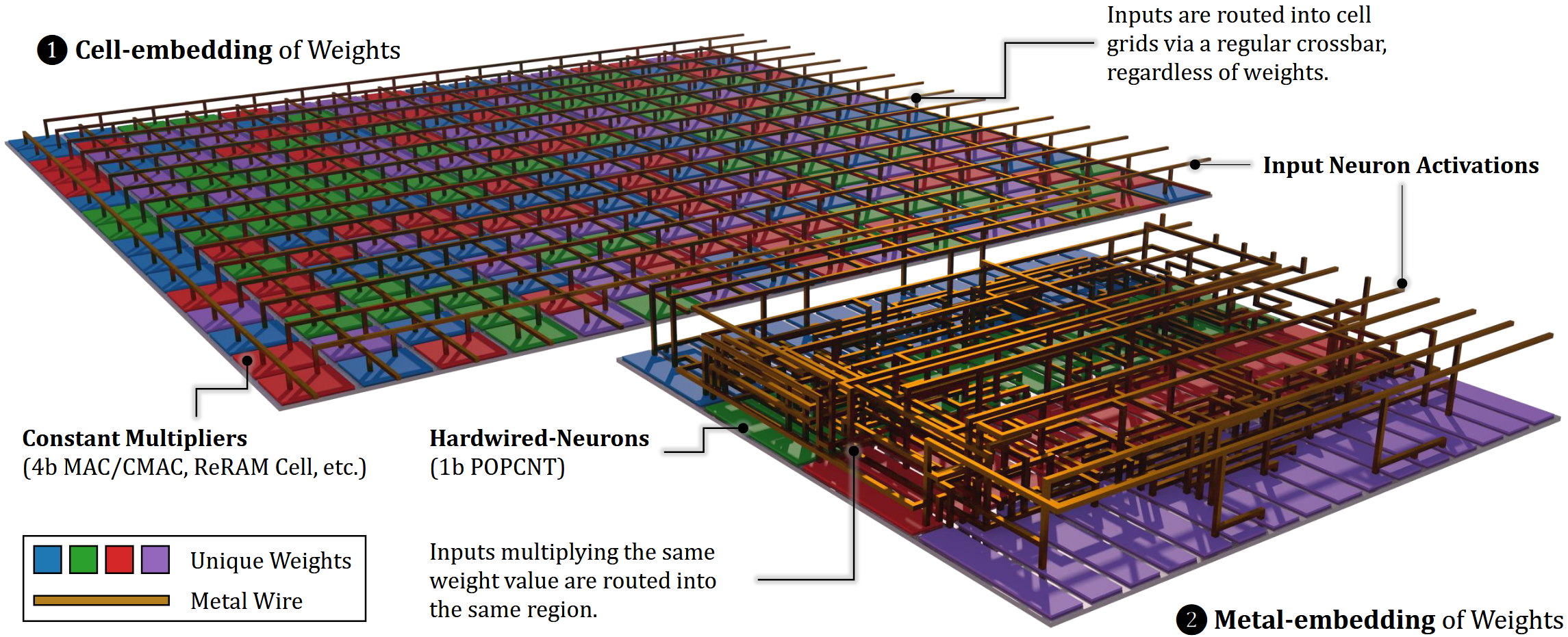
对于如何消除这种反复来节约硬件开销,学界给出过多种不同的解法。Taalas采取的策略是LUT方案,即通过预计算-选择消除重复乘。由于量化后权重取值空间极小,输入激活值与所有可能权重取值的乘积可预先全部进行一次,列出所有可能用到的积,后续每一次单独的乘法运算都可以改为从预计算结果中选取现成的值。梳理Taalas已公开的14项专利,其核心机制主要记载于《Large parameter set computation accelerator…》(US20250123802A1)中。
1.乘:首先进行预计算,将
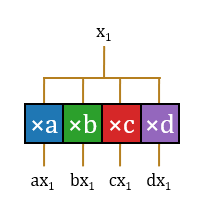
2.选:这样,
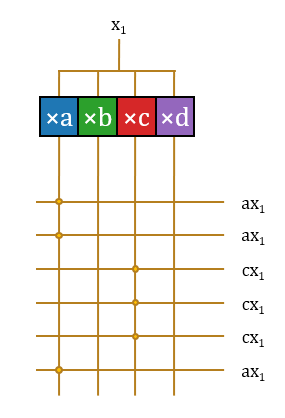
3.加:至此,该结构无重复地完成了这16项运算。这些运算分属16项不同的输出神经元激活值,因此需要16个不同的累加器累积起来。
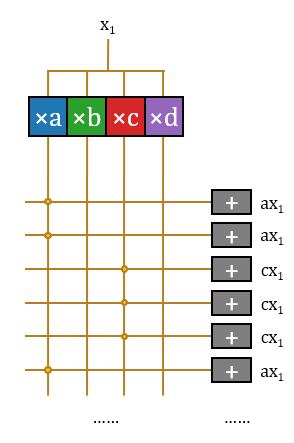
这样该结构完成了一个输入标量
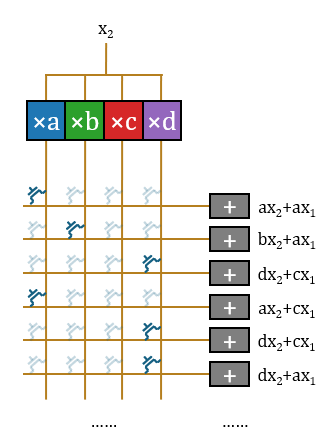
通常PTL构造传输门需要一对晶体管,但此处采用单个晶体管是合理的。单个晶体管只是会产生阈值电压降,在交叉开关阵列外、累加器前增加Buf恢复信号即可。Bajic声称公司手工绘制了一部分版图,很可能是用于处理这一部分。
晶体管的栅极需要提供独热控制向量,可以直接从ROM中读出。这样,完整的矩阵运算架构基本上已经形成。周围搭配词表查找表、随机采样、归一化、softmax、位置编码、激活函数这些辅助功能,配一个中等容量的SRAM用于存放KV(模型本身上下文很短),整个模型便完整实现了。
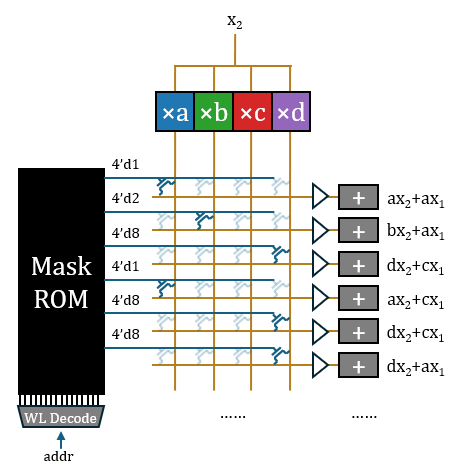
每个2比特权值转为4比特独热编码写入ROM,需要的ROM容量比较大,且不符合“store four bits away”的说法(HC1声称采用了3/6比特混合量化,如果是独热表示,至少应该“store eight bits”)。所以我认为ROM中烧录的应该是权重原值,然后通过3-8译码器转换为独热。译码器是矩阵外边的一维结构,总开销并不大。
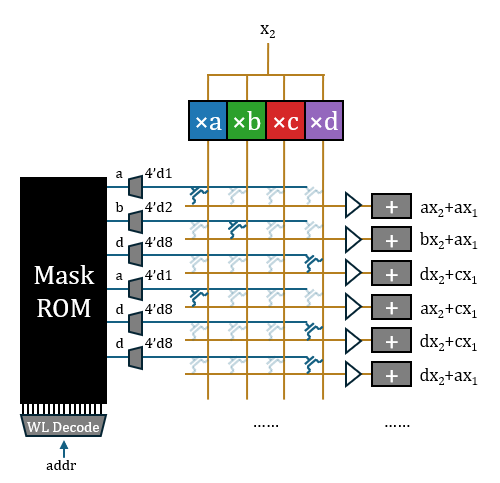
Taalas宣称定制Mask ROM需要变化两层光掩模。这很可能是用于两层Via通孔,其结构应当如图所示:受字线控制的VDD与GND互补地布满上下两层Trench,中间Trench作为读出的位线,以Via互补地在位线的上方或下方打孔来表示0或1。
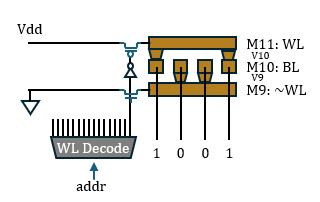
所以,Taalas方案中真正硬连线的部分只有ROM的通孔。整个架构仍可以明确地分为存储部分与运算部分,存算在结构上是分离的。它没有消除广义上的访存,只是将访存对象的介质由SRAM(Groq)、HBM(Nvidia)变为ROM,访问读取的数据也极有可能是未经处理的权值原值。如果认为访问同一芯片上的存储器不算访存,那么消除这种狭义的“片外访存”的目标其实Groq方案就已经做到了。
运算部分是一个经典的量化运算架构,与UNPU、Cambricon-P等非常相似。运用这些架构改善量化矩阵乘法效率并不需要假设权值是固定的。我放一张架构图对比供参考。
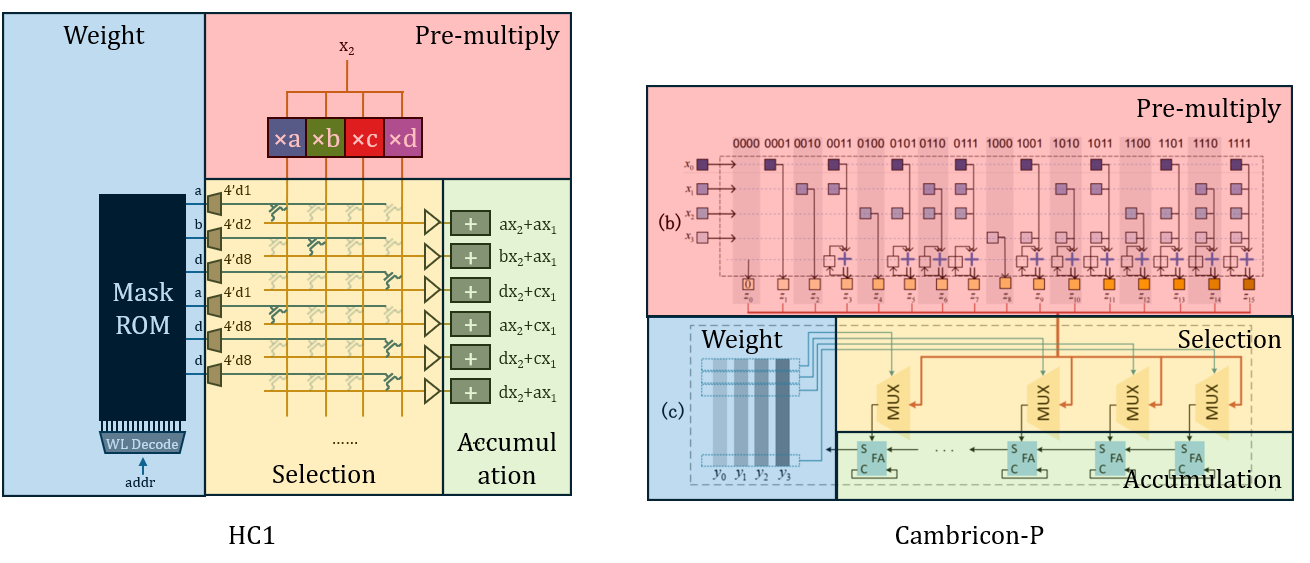
在此架构下,因为预乘法、累加、解码器、Buf这些结构都处于阵列外围,都是一维结构,所以都可以视作真正运算的准备工作或收尾工作,仅将二维的交叉开关视为真正的运算。在这种视角下,“一个晶体管完成所有运算”的说法也有一定的道理,只是略显夸大。从更严格的视角来看,它只承担了运算中的选通功能。
运算部分也可以直接用于处理变值矩阵,只要将交叉开关阵列控制信号来源由ROM切换到SRAM即可。猜测HC1就是这样支持LoRA的。这个架构可以通过调节尺寸参数,对运算器件(主要受限于晶体管元件)与存储器件(主要受限于高层金属通孔)进行面积平衡;但运算是需要通过逐行读取ROM完成的,所以一个矩阵完整处理完需要将整个ROM的所有地址遍历一遍,限制了峰值算力;如果将多个矩阵写入同一个ROM,这个架构就很难做流水并行。
密度上,由于运算和ROM存储是分离开的,比例可以随意调整,所以面积主要受限于ROM。假设ROM编码所用通孔的Half Pitch是62 nm,ROM bit-cell密度是0.015 μm²,8B平均4.0bpw的模型需要480 mm²,与实现基本吻合;如果降低几层到38 nm,密度0.0058 μm²,模型只需要约180 mm²,但无法单次曝光完成,模型更新成本会因此翻倍。由于硬连线芯片通常不需要特大规模量产,如果能与工艺配合,在产线中引入电子束光刻实现无掩膜通孔加工,有助于低成本实现高密度可变通孔;试想为芯片更换模型不再需要重新设计,只引入一两层每片成本几千元的电子束打孔工序就能源源不断流出搭载各种模型的芯片,硬连线语言处理器离落地的最后一点成本障碍就解决了。
单纯从架构设计角度而言,HC1还有许多地方值得商榷,但它真实实现了一个当下多数人尚不能接受的愿景。它本身只是一个Proof of Concept,对它的评价不应过于注重它当前表现出的智能能力。这个团队的思想已经早早转变过来,也已证明找到一条行之有效的技术路径,之后通往实现颠覆性产品的过程中还剩下的障碍已经不多了。最新前沿模型的硬连线芯片很快就会被实现,届时将对现有的AI计算范式与芯片产业格局产生深远影响。
计算机是人类发展速度最快的学科之一,在跨越式的技术进步之后,其底层思维有时会显得落后。在平常的研究工作中我们习惯于实证和量化的表达,而本文尝试借用科学哲学的视角梳理计算架构的演进逻辑。文中的批判性探讨并非旨在贬低前人在旧有范式下的成就,而是希望通过底层观念的碰撞,为读者理解通用计算的未来提供一个理性的新维度。
人类对科学的探索,始终无法脱离其所处时代的客观历史条件。正是这些条件,决定了我们认识世界的初始视角,并深刻塑造了不同学科的底层认识论。
物理学是一门关于既有实在的学科。在人类有能力砸碎原子之前,日月星辰已经运行了百亿年。所以,人类对物理学的认识路径,必然是从宏观渐入微观。早期的物理模型始于开普勒的行星运动定律,随后才被牛顿力学所解释,而对微观基本粒子的认识则要等到数百年后的近代。历史条件让人类只有在宏观模型臻于完善之后,才能逐步建立微观模型。
因此,在物理学中,任何在认识论上贪婪激进的还原主义思想,都会直接挑战当时人们的既有认知,从而容易得到充分的批判。这种思想认为:既然已经发现了万有引力,便不再需要开普勒的定律;既然确立了相对论时空观,牛顿的绝对时空观便是一种谬误;既然所有相互作用都可以还原为几种基本力、所有物质都可以还原为基本粒子,那么始于苹果落地的探索便只算作通向标准模型的多余过渡品。由于更基本的规律诞生了,便可以否定更高认识层级上宏观科学规律的价值。
然而在计算机科学,人类的认识路径是从微观进入宏观。计算机科学是一门关于人造物的学科,受限于历史时期的工程能力,计算机科学家没有如物理学家那样的历史条件去预先建立宏观认识防线,容易先入为主地接受还原主义观点的教育。这导致在物理学中已被充分批判过的认识论上的还原主义思想,在计算机科学中却被长期采纳为主流。
图灵是一个伟大的数学家,是计算机和人工智能的先驱。作为数理逻辑的分支,他的理论奠定了计算的本体论,但同时在认识论上存在着未曾被批判过的巨大局限。他的理论认为:用基本算术和逻辑可以计算一切可计算问题——如果平移到物理语境中,这句话就如同“用夸克和电子的运动可以解释第二次世界大战的结局”。一方面,这种观点在逻辑上是严谨的,展示了理论的普遍与优雅;另一方面,这种观点也否定了其他认识层级存在的意义,并巧妙地将它们的价值导向自身。
图灵认为通用逻辑计算机通过编程可以实现人类的智能;乔姆斯基认为人类的心智可以还原为一组明确的“转换-生成语法”规则;费根鲍姆认为专家系统可以通过形式逻辑与知识库的堆砌构成。在这种还原主义信念驱使下,一代又一代科学家如飞蛾扑火般扑进了一个永远研究不完的问题中:穷尽短暂一生写下有限的规则,尝试去拟合极度复杂的智能功能。然而,封闭计算系统的柯尔莫果洛夫复杂度不会自发地升高,这意味着有限的代码与逻辑规则,永远无法凭空内生出超越其自身结构的信息量与复杂性。无限的理论可能最终还需要通过有限的人力来实现,因此物理学家绝不会尝试通过摆弄夸克来复现斯大林格勒;但计算机科学家在本体论上的成功长期掩盖了其在认识论上的原始,他们失败的结局是注定的。
最终,这些信念随着日本五代机的最后努力一同破灭,但也留下了一些改变世界的副产物:图灵的理论是今天信息社会的基石,通用数字逻辑计算机是今天人类再也无法离开的工具;乔姆斯基的理论虽然解释不了人类心智,却形成了“形式语言与自动机”这门分支,成为了现代编译器的基础;费根鲍姆因在早期人工智能系统中的贡献于1994年获图灵奖。
在体系结构领域,计算还原主义思想长期驱动着一股反动力量,压制着新架构的诞生。在这种思想下,专门针对基本数学运算与逻辑跳转而设计的CPU是实现通用计算机的最佳实践。由于CPU已具有完备的功能——由图灵所保证,同时发展其他架构便没有意义。直到21世纪初,CPU几乎是这门学科所研究的唯一对象。
这种思想对新兴架构的压制是毁灭性的。因一切计算都预先在思想上被还原了,任何有别于CPU的架构的价值已被先决地否定,最多只能作为“仆从设备(Slave)”存在。你可以设计一个专门的视频编码器,然后以二等公民的身份挂载在CPU外围,补充CPU的性能。在量化研究方法下,它的价值体现在464.h264ref这一单项测试的评分提升上。因为只影响无穷多程序中的一项,这会被视为无关紧要;因程序会演变,这会被视为临时方案。
CPU独特的通用性被认为是长久适应程序变化的唯一万全之策。新架构或许会调和地转而证明自己也具有图灵完备性,希望借此获得同等严肃的对待。但它们会落入一个专门用来审判这种调和思想的概念中:“图灵坑(Turing tar-pit)”——这个概念由首届图灵奖得主阿兰·佩利命名,指仅具理论可能而不具有实际意义的通用性。
在还原主义观点下,深度学习也被长期异化为广泛程序中的平凡一例,被视为052.alvinn——与464.h264ref没有本质区别。因此,专门研制针对052号程序的处理器芯片被视为缺乏远见的行为,因为人们认为无法预测明天智能算法会不会从深度神经网络发展成支持向量机,导致芯片在诞生前就失去价值。在快速崛起的深度学习面前,还原主义对通用性的坚守带领整个产业进入一个悖论:深度学习发展势头越盛、研究深度学习处理器就越无意义。这样僵持到2011年,竟然出现了谷歌使用数万个CPU训练识别猫的奇景。
然而历史的演进已经证明,深度学习处理器最终跨越了附属地位,发展为一项影响深远的产业。这是因为深度学习并非对既有计算程序的简单堆砌,而是代表着人类认识计算的另一层级。它具有同样深厚的理论根基,构成了另一种截然不同的通用计算范式:
第一类通用性(数学逻辑):以通用图灵机(希尔伯特判定问题)为理论基础,基于离散状态、离散计算、符号表示,旨在判定数学中能够递归定义的所有逻辑命题。它通过被动地接受编程来实现通用,擅长处理各种能够由规则清晰描述的繁重重复逻辑。
第二类通用性(深度学习):以通用近似定理(希尔伯特第十三问题)为理论基础,基于实数状态、实数计算、数据分布概率,具有逼近任何定义在欧式空间上的连续函数的能力。它通过反向传播训练来实现通用,能够解决人类无法显式描述规则、但可以通过数据学习的智能任务。
近来,一种颇权威的说法将深度学习处理器描述为“领域专用架构(DSA)”并广泛流传。依我来看,”领域专用架构“这个概念是一种旧观念下的异化与新观念带来的现实之间妥协的产物。一方面,它承认了过去将深度学习异化为“一种平凡程序”的错误,给深度学习处理器的发展让出了空间;另一方面,它只愿意修正至“一种平凡领域”,以便仍尊(第一类通用架构)CPU为主不变。深度学习处理器诞生已十余年,多种“领域专用架构”百花齐放的新黄金时代是否如约来临了?哪种观点更好地解释了现实,每位读者都可以有自己客观的判断。
谷歌训练识别猫的任务,交给一颗CPU几乎永远无法完成,交给一颗深度学习处理器则轻而易举。但是,形而上学的计算还原主义者坚称只有前者才是通用的——他们认为CPU甚至能够支持至百年后的人工智能。这种观点中的荒谬之处,就如同认为物理学家能诊疗疾病。以智能计算的视角观之,CPU也只是一个“图灵坑”罢了。
前段时间,我受陈云霁老师的委托,协助他总结回顾这段科学发展史。我惊奇地发现历史是一个轮回——我曾认为自己走在孤独的路径上,却处处都是前辈留下的脚印。
在我的观点中,今天的深度学习大语言模型已经初步实现了通用人工智能,只是尚未形成广泛认同。因此,我预测以大语言模型为基础,即将诞生第三类通用计算范式,即基于自然语言的认知智能。它基于自然语言、上下文理解实现通用,擅长处理宏观规划、常识、逻辑思考与交互。这是目前已知唯一能实现高级认知功能的计算途径,已经非常接近人类智能的表现。
通过研究高效、低成本的硬连线方案,直接工作在自然语言词元上的语言处理器,相比深度学习处理器(包括GPU)可以再次实现千倍以上的效率提升。千倍效率提升已不再只是量变,而是开启了新的计算层级,实现了具有高级认知能力、能够实时响应的硅基大脑。这种级别的计算效率过去被广泛认为需要切换到模拟电路、光计算、新材料等不同技术路线,而我们的方案基于标准CMOS工艺实现,具有快速落地应用的潜力。
技术上,我们已经基本找到了一条可行路径并持续推进,但真正的困难在于扭转过去长期形成的既有观念。正如深度学习处理器需要面对被异化的历史,在当下业界注意力全部聚焦于以天量投资大建“星际之门”的时候,这种新型语言处理器也需要首先克服误解。由于缺乏对可能形成的“第三类通用计算范式”的广泛认识,大部分系统研究者习惯性举起的是旧观念下的标尺。
如同过去曾有人认为深度学习只是SPEC中的一号程序,今天也会有人认为单个大语言模型只是Mlperf中的一个平凡模型——例如Llama3.1 8b之类。但是,语言能力本身便是通用智能的重要形式,其解决一般问题的能力与价值已无需赘述。通过具体哪个模型来实现这样的语言能力,已经是一项类似“选用哪家厂商供应的CPU”一样次要的技术问题。
在两个时期均有反对者声称,当下的算法正处于剧烈动荡期,押注一个特定算法是危险的。然而,深度学习处理器通过总结运算的基本规律,能够实现针对深度学习算法的广泛支持,并没有因模型结构由AlexNet到ResNet到ViT的变化而消亡,将支持向量机运行在深度学习处理器上也本就不是一件难事。语言处理器并不是简单对模型进行无序的固化,而是提取了其中的重要计算规律进行针对性设计,为最主要的前馈网络与投影部分提供通用于矩阵-向量运算的硬连线模板,辅以可控制的其余辅助单元共同完成计算。一块神经元海基板完全可以做到同时支持多种Transformer或其他神经网络模型,支持Mamba也并无技术困难。
当前产业界最难以打破的偏见。面对大语言模型日新月异的发展,人们本能地退回到一种具有绝对灵活性的架构中寻找安全感。在过去,这个避风港是CPU;在今天,这个避风港变成了GPU,也即形成了新的“大语言模型发展势头越盛、研究语言处理器就越无意义”的悖论。
GPU为了适应快速发展,打造了一整套厚重的软件栈(驱动-运行时-编程语言-算子库-框架-推理系统),维护整套软件生态持续运作的巨额成本是GPU当前最强的垄断壁垒。到了大语言模型的时代,整套昂贵的软件生态最终却仅服务于GPT、Gemini、DeepSeek等少数几个模型的集中部署,资源配置效率非常低。
而在语言处理器中,硬件直接工作在词元层面上,消解了软件生态成本。在当前技术方案下硬件开模成本也可以得到良好控制,随模型更新重置一套硬件的成本可以做到显著低于新模型本身训练的成本。“通过更换硬件实现模型更新”在历史上从未作为现实方案出现过,因此要让人们广泛接受还需要更多的时间来发展。
另一方面,假设摩尔定律加速发展,集成电路的性能每隔几个月就会翻倍,导致一颗CPU在上市前其工艺就已不再是最先进的。在这种情况下,我们会不会将CPU的制造也停下来?请注意,语言处理器的更新不会改变其自然语言界面,而只会改善其在部分任务上的性能。能够通过性能淘汰一颗语言处理器的,只有另一颗语言处理器。
图灵终其一生都在为人造机器终将实现人类智能的信念而辩论,他孜孜不倦地撰文逐一反驳神学、有灵论、“草莓加奶油”、心灵感应等在今天看来已极其荒诞的观点。他乐观地写道:“我相信在世纪之交,词语的使用与普遍的学术观点将已经发生巨大的改变;到那时,人们将可以谈论机器思考而不会引起什么异议。”
图灵本人曾坚信通用性已经意味着逻辑计算机可以达到人类的智能,但晚期的他也意识到了将人类智能简单归结为在计算机上编写程序的困难。他曾这样写道:“通用逻辑计算机只是一种极端纪律化的形式;要让机器产生人类智能,应当制造一种无组织机器,然后通过奖惩系统对其进行教育。”这种新机器的形式与今天深度学习有着惊人的相似,然而由于对于体系结构所研究的CPU量化指标竞赛没有直接帮助,他的观点只被今天计算机科学的教育系统选择性地吸收了前半部分。由此可见,在计算机这样一门年轻的学科中,我们过去被教育过的知识并不见得总是全部的真理。创新意味着必须不断地重新敲打每一项既成共识。
虽然图灵没能直接实现人工智能,但假若没有过去作为工具的通用逻辑计算机辉煌发展,便没有深度学习的诞生和复兴,更没有今天我们有幸见证的通用人工智能雏形。计算机科学在经历了近百年的底层微观堆砌后,终于借助大语言模型真正触及宏观的“认知”层面。自语言处理器之后,我们的造物不再只是计算数字,而是开始通过语言的形式深度思考。这是整个学科从计算机的“工程学”向“认知科学”演进的重要转折点。
历史将这个重要的转折点交给了我们这一代架构师。语言处理器架构在既有观念下是那么不可理喻;可切换了观念视角后重新审视,它又是那么直观。希望十年之后,当人们回顾这个架构的时候,都能够觉得这不过只是当然。
我们关于硬连线LPU的论文已被计算机体系结构顶级会议 ASPLOS 2026 接收。在论文中,我们将大语言模型(LLM)直接硬连线制造于芯片电路结构之中,创造了一种全新的处理器形态“硬连线LPU”,其能效相比现有GPU实现了超过一千倍的提升。
在集成电路领域,将神经网络硬连线并不是新鲜事。自上世纪80年代起,这一构想就反复被提及,却因缺乏通用性而始终未能形成产业影响。以这些历史经验来套用未来,便形成了一种惯性智慧:“看,那些搞极端专用硬件的都失败了。英伟达之所以称霸,正是因为GPU处于通用性与效率的完美甜点(Sweet Spot)上。”
事实上,在现实世界中,“通用性”是一个工程经济学命题:它要求计算机创造的价值必须覆盖其工程成本,如不满足,那么这种新型计算机便不会存在。除此之外,没有任何物理铁律规定计算机硬件必须支持软件更新才能运转。试想,如果你突发奇想制造一台只能计算特定哈希函数的机器,这在教科书看来简直是离经叛道;但在现实中,只要合于利而动,不能更新又有何妨?多年后,那些思维开放、行动敏捷的人通过制造这种机器已经赚得盆满钵满,而旁观者只能在质疑中错失良机:“明天协议改成PoS了怎么办?你难道要再造一台吗?”
因此可知,一颗处理器的价值不在于它能支持多少种程序或更换多少代模型,而在于它是否找到了价值足够大的任务,哪怕只有一项。今天历史条件已悄然改变,人类获得了第一个值得被硬连线实现的神经网络——ChatGPT。现在,LLM所创造的应用价值已无需赘述,我们可以直观地量化:一台加密货币专用机每秒获得的收入不足一分钱;而按现行定价,一台硬连线LPU节点每秒创造的收入可达20元。
即使如此,也总有人会怀疑:“LLM迭代那么快,明天算法改成Mamba了怎么办?你难道要换硬件吗?”
为什么不呢?过去计算机强调软件更新,是因为软件迭代的边际成本几乎为零。但今天,训练一个具有竞争力的LLM所需的资本投入,已经历史性地超过了先进工艺芯片的改版费用。在这种条件下,更贵重的模型才是企业的核心资产,而芯片相对模型而言已是耗材。如果LLM的应用价值足以推动企业按季度甚至按月发布新模型,那么将一批定制处理器与旧模型一同淘汰,其经济损失是低微的。相比于丢弃芯片带来的只占小部头的额外成本,专用硬件带来的收益却是变革性的。一台硬连线LPU节点大约可替代由2000块H100构成的GPU集群。由于所需芯片数量大幅减少,数据中心的土建、运维、电力以及具形碳排放均可实现数百数千倍的节约。面对无序增长的推理需求,制造“月抛”型硬件、通过物理更换来实现模型更新,反而必将成为一种更经济、更环保的选择。
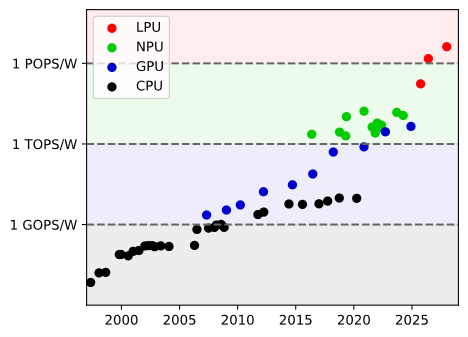
在我们看来,虽然技术上采用了最不可变动的方式来实现,但硬连线LPU仍是一种通用(General-purpose)处理器。它实现的是一般功用的LLM,因此硬件便自动连带获得了一般功用性;它在硬件层面直接实现对词元的处理,指令与数据都以提示词的形式输入来实现对通用问题的编程。它的软硬件界面(ISA)是自然语言,是无法被个别企业排他性使用的,也不再需要CUDA等软件的辅助,天然地消除了生态垄断的问题。它的计算能效可达到1 POPS/W量级,形成继CPU(标量,MOPS/W)、GPU(向量,GOPS/W)、NPU(矩阵,TOPS/W)之后的第四种通用处理器范式(词元,POPS/W)。
在有了原始构想之后,技术方案并不是短时间内就能简单取得的;对于同行而言,在完成整条路径的探索之前,这个构想听起来一直都过于不切实际。因此,自ChatGPT诞生以来不断地有人、有企业提出类似的想法、又很快全都放弃。据我们所知,UIUC、ARM、密歇根大学、东京大学在研究类似技术,均无法达到足以支持LLM的水平;初创公司Etched、Taalas等曾公开宣称要推出类似产品,迄今未获成功。我们的团队自2023年3月起开始研究能够实现硬连线LPU的合理技术方案,跨越算法、架构、工艺多个研究领域、有机结合了两项关键创新后才使预估成本降低至合理范围:
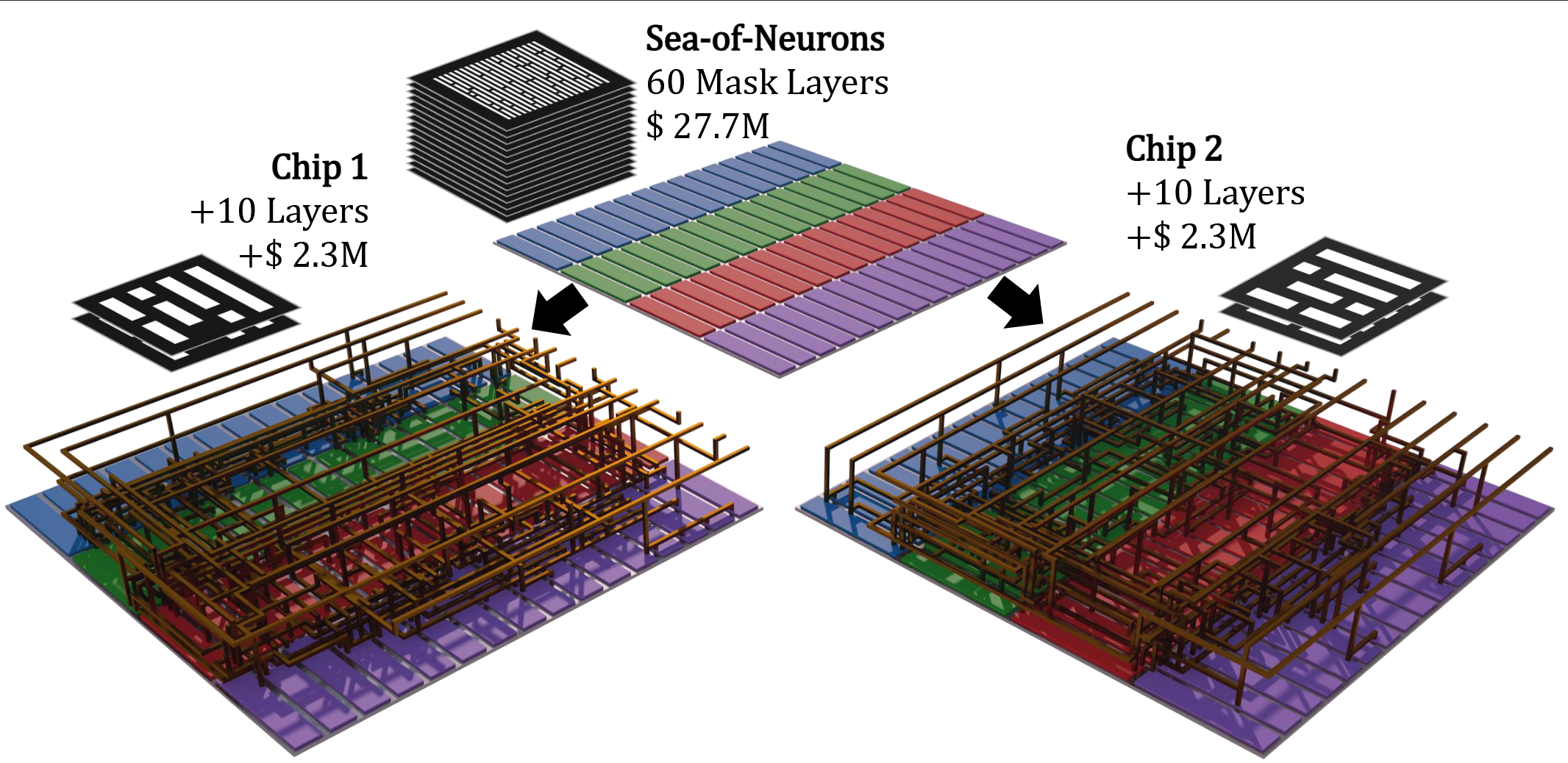
学术原型系统“HNLPU”经过版图后仿真验证,在5 nm工艺、16×827 mm² 面积条件下,完整实现了OpenAI开源模型GPT-OSS 120B,保持了该模型原生采用的FP4数值格式精度。在单卡对比中,其性能、能效分别达到了英伟达H100的5555倍和1047倍;在每年更新一次硬件的大规模部署场景下,HNLPU相比GPU集群,运营成本、总成本、碳排放总量优势分别可达1496倍、41.7倍和357.2倍。
硬连线LPU是这样的一种处理器范式:它具备通用的、可编程的器件(用于计算注意力、位置编码、激活、采样等),具备一套用于存储键值序列的存储层次结构,具有横跨多芯片的高速互联系统,以及一个巨大的常值矩阵运算部件(HN阵列)。HN阵列的共有结构在上游企业预制,在下游企业确定LLM模型权重并下订后,再完成金属化将权重写入,快速而低廉地生产出搭载各个模型的超高效能芯片。我们预计这种新产业模式将取代GPU在长期、大规模推理部署市场的垄断地位,但同时也需要模型企业、芯片设计企业与芯片制造供应链之间进行尽可能强的深度整合。虽然还面临许多挑战,但历史上曾在芯片产业占据一席之地的结构化ASIC和门阵列(英特尔至今仍经营着eASIC业务),证明了这条路原本是可行的。
今年,我们预计将继续发布微调架构方案以及新的版图设计方案,实现低成本的模型容错和热修补,并将更换模型的改版成本再次降低十倍以上。同时,我们也在积极推进概念验证原型系统的试制。在国家重点研发计划的支持下,我们正在以国产工艺制作基于HN结构的硬连线人机交互处理器芯片,预计将实现不低于 1.5 POPS/W @ FP4 的计算能效。该芯片有望成为世界上计算能效最高的标准CMOS数字逻辑芯片。
敬请各位同仁关注我们的最新进展。
(本文部分内容截取自《硬连线LPU:大语言模型时代的处理器芯片新范式》初稿,原作者为:赵永威、郝一帆、刘洋、陈亦、陈云霁)
前段时间,全重筹划开展智能电路设计工作,准备材料时经常需要一些电路原理图作为示例。 然而却没有现成的工具方便绘制这些原理图。 现有画原理图的工具需要一个一个元件手工码放、一条一条线手工连接,画一个小规模示例都需要非常繁重的操作。 4位加法器就包含了上百个晶体管,更大规模的例子手工码放,成本都快要接近从头设计一个4004了。 而真实的综合、布局布线工具不仅调用繁琐,最终画出的图也不美观。 因此,我一直以来都是自己写脚本来绘制这些图。
一开始是在Python中,通过PIL来画。 写了几个基本的函数,能在指定位置绘制晶体管和逻辑门, 但布局布线仍然需要手工设计,工作效率不高。 于是我决定给脚本加上简单的布局布线逻辑,实现从输入电路网表到输出原理图的全流程自动化。 以下是最终效果:

涉及到布局布线这样比较繁重的运算流程,我立刻决定抛弃Python,改用C++来实现,不然画一张图要等一天。 布线算法挪用了之前曾为绘制另一幅图写过的迷宫布线。 然后我直接将布线的代码贴给DeepSeek,让它给我补全布局的代码。 DeepSeek-V3-0324展现出非常强的代码能力,写出的代码立刻就能运行,功能完整。 在大语言模型的帮助下,加上一些搜索和一点巧思,抛弃PIL也并未带来多少痛苦。 DeepSeek提供了输出PNG的代码、抽取BDF点阵字体的代码,帮我调试了斜线栅格化算法中的Bug。
因此,我很快实现了这份约800行的自动电路布局布线程序,输入BLIF、输出PNG。 它完全自包含,依赖仅限于C++标准STL。 即使从小就在写程序,这次编码经历对我来说是全新的,展示了大语言模型时代对编程体验的重塑。 如果不是有大模型,去阅读PNG、BDF、DEFLATE这些标准的RFC然后去写底层函数,是非常痛苦的,我是断然不会去尝试的。
抛弃Python回归C++从未如此简单,想必抛弃CUDA亦如是。 在这个时代,生态壁垒正在被全方位削弱,这是令人兴奋的趋势!
用到了C++26。当前只有GCC 15.0能编译,但15.0尚未发布,我为此从源码编译了最新的GCC。
这是我第一次大量使用ranges库,体验很好,很多时候能节省大量不必要的啰嗦。
当前的ranges还缺一些功能,例如反向的drop(从区间尾部去除一定数量的元素);
想从循环中得知是否是循环的第一次/最后一次执行还不方便,不如过去的旧写法。
C++标准还缺乏一些关键容器,比如不知为何至今没有trie?
一些老容器的性能一直被人诟病,也是时候翻新一遍了。
最新标准已经提供了flat_map,只是在我的场景里测试下来未见有性能优势;未见unordered_flat_map。
希望这些新功能要避免重走regex的老路才好。
1 | /* ============================================================================ |
附一段DeepSeek-R1对代码的解析:
这个程序是一个用于生成标准CMOS电路原理图的工具,支持从BLIF格式输入并输出PNG图像。以下是其核心功能和工作流程的解读:
输入解析(
parse函数)
- 功能:解析BLIF文件,提取电路的输入、输出端口及逻辑门信息。
- 关键数据结构:
inputs/outputs:存储输入/输出端口的ID。gates:以哈希表形式存储逻辑门,键为门ID,值为门类型(如NOT、NAND)及其连接的端口列表。names:将门类型名称映射为唯一ID,支持动态扩展。- 处理逻辑:
- 通过逐行解析
.inputs、.outputs和.subckt段,提取端口和子电路信息。- 使用
parse_name函数将字符串类型的门名称转换为整数ID,便于后续处理。布局优化(
place函数)
- 算法:基于模拟退火算法进行布局优化,目标是最小化布线成本和面积。
- 关键参数:
initial_temperature:初始温度,控制算法早期接受较差解的概率。cooling_rate:冷却速率,逐步降低温度以收敛到最优解。area_cost和cross_track_penalty:分别惩罚面积和交叉布线。- 流程:
- 初始布局:随机生成门的位置,确保无重叠。
- 迭代优化:通过调整门的位置,计算新的布局成本,根据Metropolis准则接受或拒绝新解。
- 终止条件:温度降至阈值或超时。
布线(
route函数)
- 目标:为逻辑门之间的连接生成路径,避免冲突。
- 关键步骤:
- 障碍标记:使用
mask数组标记不可布线区域(如门周围的空间)。- 路径搜索:基于BFS算法,从目标端口反向搜索到源端口,记录路径。
- 成本计算:累加路径长度和交叉轨道惩罚。
- 输出:
paths:存储所有连接的路径坐标。
solders:记录焊点位置。绘图(
draw_t结构体)
- 功能:将布局和布线结果绘制为PNG图像。
- 核心方法:
- 基本图形:
line、ellipse用于绘制线段和焊点。- 逻辑门绘制:
nmos、pmos、inv、nand等函数实现CMOS门的具体绘制。- 文本标签:
text函数利用预定义字体位图标注端口名称。- PNG生成:通过手动构造PNG文件格式(包括IHDR、IDAT、IEND块),结合DEFLATE压缩和CRC校验,输出最终图像。
主流程(
main函数)
- 解析输入:读取BLIF文件,提取电路信息。
- 布局优化:调用
place生成初始布局。- 网格对齐:通过
snap_to_microgrid将布局坐标对齐到微网格。- 多次布线尝试:逐步增加松弛度(
slackness),调用route进行布线,直至成功。- 生成图像:成功布线后,调用
draw_schematic绘制原理图并保存为PNG。关键技术与挑战
- 模拟退火算法:平衡全局搜索与局部优化,避免陷入局部最优。
- 路径搜索算法:在动态障碍环境中高效寻找可行路径。
- 低层级绘图:直接操作像素数据并生成符合PNG标准的文件,需处理压缩和校验细节。
总结
该程序通过解析电路描述、优化布局、自动布线和绘图,实现了从逻辑描述到原理图的自动化生成。其核心优势在于结合了算法优化(模拟退火)与底层图形处理,适用于中小规模CMOS电路的快速可视化。
输入读取的是BLIF格式的网表。 可以用开源的Yosys,从Verilog综合得到。
例如先让DeepSeek给我写一个4位加法器作例子:
1 | module adder4 ( |
写一个标准单元库。 当前我在代码里只放了非、与非两种门,要告诉Yosys只用这两种单元。
1 | library(demo) { |
启动Yosys,在其中运行这些命令:
1 | read_verilog adder4.v |
最后一步会输出BLIF格式的网表,复制保存到文件adder4.blif里。
1 | # Generated by Yosys 0.51+104 (git sha1 c08f72b80, g++ 13.3.0-6ubuntu2~24.04 -fPIC -O3) |
编译cirschem.cpp:g++ cirschem.cpp -std=c++26 -O3
运行:./a.out adder4.blif
稍等半分钟布局布线完成,输出保存为schematic.png
随着大语言模型的兴起,受算力和存储预算所限,4比特量化模型正成为大语言模型部署的首选。然而,我们观察到,传统计算架构在处理低精度矩阵乘法时存在严重的计算冗余问题。 我们提出Cambricon-C架构,通过创新的 原初化矩阵乘法(Primitivized MM) 算法,有望彻底改变4比特矩阵计算的实现方式。
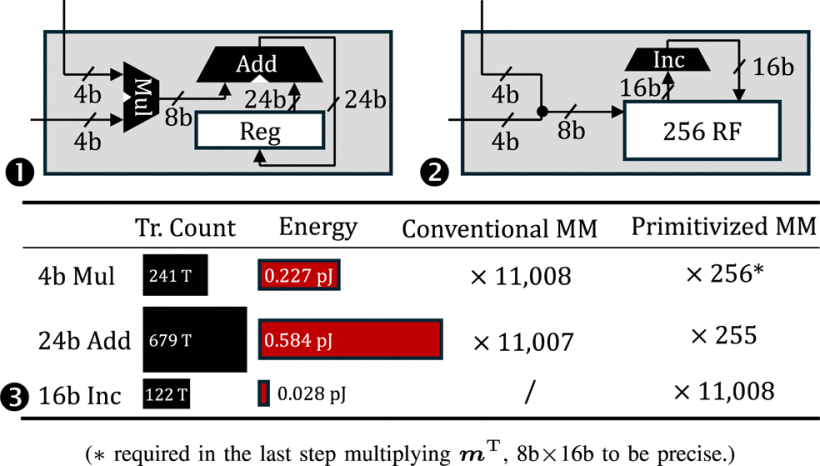
对4比特矩阵乘法的运算过程进行深入分析,就会发现惊人的冗余:在Llama2-7B的4比特量化版本中,完成单个输出神经元激活值需要计算11,008次4比特乘法并累加到一起。而4比特数据最多仅有16种可能值,根据鸽笼原理,超过97%的乘法必然是重复发生的。传统基于MAC单元设计的矩阵运算器会重复计算这些相同乘积,意味着巨大的能耗浪费。
PMM算法则提出:根据乘累加运算的逆分配律,先统计各项乘法出现的次数,最后统一加权求和,大幅削弱计算强度。
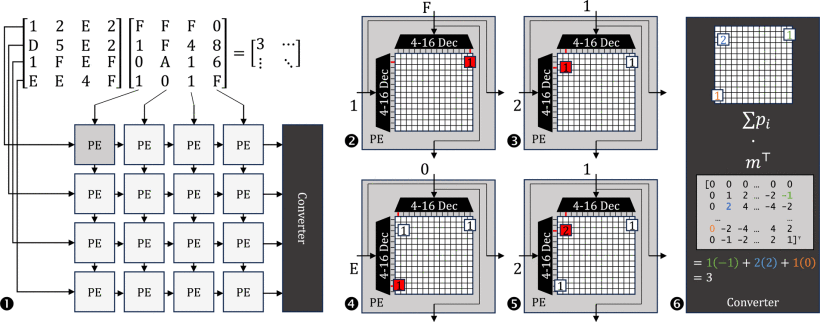
基于PMM算法,我们设计了Cambricon-C架构:
实验结果显示:
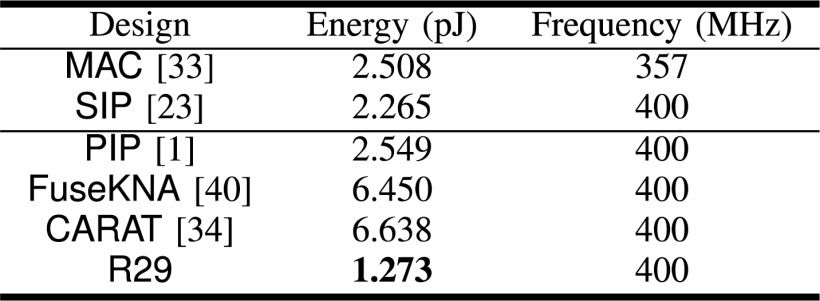
Cambricon-C开创了”原初化运算”的新范式,通过将复杂运算分解为最基础的计数操作,我们重新探寻了低精度计算的效率极限: 未来加速器的运算效率不再取决于精巧的MAC单元设计,而需要将整个矩阵运算通盘考虑、整体优化。 在不远的将来我们还将公开发表更多关于“原初化运算”的工作,持续推动深度学习处理器底层微架构的革新,希望获得各位同行关注。
给定一个棋盘格局,找出所有的威胁点。威胁点是指双方各自落子后能形成必胜局面的点,例如冲四的一端(必胜,落子后立刻形成五子连珠)、活三的两端(落子后形成活四,若对方此步不胜则下一回合必胜)。例如下面这个棋盘中标“x”的位置。
┌┬┬┬┬┬┬┬┬┬┬┬┬┬┐
├┼┼┼┼┼┼┼┼┼┼┼┼┼┤
├┼┼┼┼┼┼┼┼┼┼┼┼┼┤
├┼┼┼┼┼┼┼┼┼┼┼┼┼┤
├┼┼┼┼┼┼┼┼┼┼┼┼┼┤
├┼┼┼┼┼┼┼┼┼┼x┼┼┤
├┼┼┼┼┼┼┼┼┼●┼┼┼┤
├┼┼┼x○○○○●┼┼┼┼┤
├┼┼┼┼┼┼┼●┼┼┼┼┼┤
├┼┼┼┼┼┼x┼┼┼┼┼┼┤
├┼┼┼┼┼┼┼┼┼┼┼┼┼┤
├┼┼┼┼┼┼┼┼┼┼┼┼┼┤
├┼┼┼┼┼┼┼┼┼┼┼┼┼┤
├┼┼┼┼┼┼┼┼┼┼┼┼┼┤
└┴┴┴┴┴┴┴┴┴┴┴┴┴┘
在AI程序的搜索中,如果出现这些威胁点,必须快速找到,以便裁剪掉其他着法。 因为有威胁点时仍着于其他位置总会导致不利。
简单的解决方法是按照规则进行遍历。我相信大部分人初次上手编写程序都是这样解决的,我也一样,毕竟过早优化是万恶之源。 但是最终你会发现这一过程的速度对AI的表现而言是至关重要的。
首先容易想到的解决方案是向量化。
用位棋盘(bitboard)作格局表示,将棋盘分为黑、白两盘,每一盘都是225个比特,可以装在uint16_t [16]中,或一个YMM寄存器__m256i中。
通过_mm256_slli_epi16/_mm256_srli_epi16(VPSLLW/VPSRLW)等向量指令对整个棋盘进行移动、对齐,然后进行逻辑与,寻找活四、冲四、活三。
这样节省了遍历盘面的开销,但由于棋形复杂(冲四、活三都不一定是连续的,可能有眼),程序并不简单,仍然需要比较长时间。
2014年,我独立发现了一个解决方法,并运用于kalscope第二版“Dolanaar”起的评估函数中。 这个程序是我本科时练习调优的习作,但也在当时取得了不错的棋力。
我将棋盘的每条阳线(横向、纵向的线)分开看待。
一条阳线上有15格,我将一行上所有可能的格局都列出,提前计算威胁点,形成查找表。
但是以位棋盘表示的话,一条阳线的编码可达0b00、白子“○”0b01、黑子“●”0b10,而0b11是非法的。
要实现紧凑编码,需要采用三进制计数,0表示空,1表示白子,2表示黑子,每个三进制位表示一个格子。
进制转换涉及大量除模运算,由二进制位棋盘转三进制开销大,是不现实的。
注意到棋盘格局并非突然出现,而是总由空棋盘逐步落子形成,三进制表示可以增量维护。
空棋盘编码为0;在第power3。
1 | constexpr int power3[16] { |
查找表threat_lut紧密编码了15格阳线的所有可能格局,仅占据27.4 MB内存。
这个方法为标准15路棋盘设计,但彼时Gomocup规则是20路棋盘,导致这个方法无效,不然当时可能我也会去参赛。 我不确定是否有其他人率先发现了类似方法,不过我确实注意到最近赢下Gomocup大赛冠军的Rapfi也在程序的一些地方使用了这一技巧。
这个方法不完美。它只适用于固定15格的阳线,用在Gomocup的20格规则就会导致查找表过大。 另外,阴线(对角、反对角线)每一条都有不同长度,如果生硬套用15格阳线的查找表会导致误报。例如在总长度只有4格的阴线上,即使形成活三也不构成威胁,因为棋盘边界会自然堵截它。这该如何处理?
十年前的我没有给出答案,留下一个未解难题。
去年,我指导博士研究生郭泓锐完成了Cambricon-U,采用偏斜二进制编码实现了在SRAM中原位计数的功能。 偏斜记数法不仅可以用于二进制,也可用于三进制,解决上述三进制编码遗留的阴线表示问题。
偏斜三进制允许数位中暂时存在一个“3”而不向前进位。 计数时,如果各数位中不存在“3”,则将最低位递增1; 如果各数位中存在“3”,将“3”归零并向前进位。 在这样的计数规则下,容易发现偏斜三进制存在以下两项性质:
我们以“0”表示空格,“1”表示白子,“2”表示黑子,“3”表示棋盘边界,即可自然而紧凑地将各种长度的阴线编入到查找表中。 阴线的长度不满15格时,只使用高位,将边界置“3”,更低位置“0”。 查找表内各项按照偏斜三进制计数顺序编纂:
| 十进制编号 | 偏斜三进制编号 | 棋盘格局 | 威胁点 |
|---|---|---|---|
| 0 | 000000000000000 | ├┼┼┼┼┼┼┼┼┼┼┼┼┼┤ | 0b000000000000000 |
| 1 | 000000000000001 | ├┼┼┼┼┼┼┼┼┼┼┼┼┼○ | 0b000000000000000 |
| 2 | 000000000000002 | ├┼┼┼┼┼┼┼┼┼┼┼┼┼● | 0b000000000000000 |
| 3 | 000000000000003 | ├┼┼┼┼┼┼┼┼┼┼┼┼┤▒ | 0b000000000000000 |
| 4 | 000000000000010 | ├┼┼┼┼┼┼┼┼┼┼┼┼○┤ | 0b000000000000000 |
| 5 | 000000000000011 | ├┼┼┼┼┼┼┼┼┼┼┼┼○○ | 0b000000000000000 |
| 6 | 000000000000012 | ├┼┼┼┼┼┼┼┼┼┼┼┼○● | 0b000000000000000 |
| 7 | 000000000000013 | ├┼┼┼┼┼┼┼┼┼┼┼┼○▒ | 0b000000000000000 |
| 8 | 000000000000020 | ├┼┼┼┼┼┼┼┼┼┼┼┼●┤ | 0b000000000000000 |
| 9 | 000000000000021 | ├┼┼┼┼┼┼┼┼┼┼┼┼●○ | 0b000000000000000 |
| 10 | 000000000000022 | ├┼┼┼┼┼┼┼┼┼┼┼┼●● | 0b000000000000000 |
| 11 | 000000000000023 | ├┼┼┼┼┼┼┼┼┼┼┼┼●▒ | 0b000000000000000 |
| 12 | 000000000000030 | ├┼┼┼┼┼┼┼┼┼┼┼┤▒▒ | 0b000000000000000 |
| 13 | 000000000000100 | ├┼┼┼┼┼┼┼┼┼┼┼○┼┤ | 0b000000000000000 |
| 14 | 000000000000101 | ├┼┼┼┼┼┼┼┼┼┼┼○┼○ | 0b000000000000000 |
| 15 | 000000000000102 | ├┼┼┼┼┼┼┼┼┼┼┼○┼● | 0b000000000000000 |
| 16 | 000000000000103 | ├┼┼┼┼┼┼┼┼┼┼┼○┤▒ | 0b000000000000000 |
| 17 | 000000000000110 | ├┼┼┼┼┼┼┼┼┼┼┼○○┤ | 0b000000000000000 |
| 18 | 000000000000111 | ├┼┼┼┼┼┼┼┼┼┼┼○○○ | 0b000000000000000 |
| 19 | 000000000000112 | ├┼┼┼┼┼┼┼┼┼┼┼○○● | 0b000000000000000 |
| 20 | 000000000000113 | ├┼┼┼┼┼┼┼┼┼┼┼○○▒ | 0b000000000000000 |
| 21 | 000000000000120 | ├┼┼┼┼┼┼┼┼┼┼┼○●┤ | 0b000000000000000 |
| 22 | 000000000000121 | ├┼┼┼┼┼┼┼┼┼┼┼○●○ | 0b000000000000000 |
| 23 | 000000000000122 | ├┼┼┼┼┼┼┼┼┼┼┼○●● | 0b000000000000000 |
| 24 | 000000000000123 | ├┼┼┼┼┼┼┼┼┼┼┼○●▒ | 0b000000000000000 |
| 25 | 000000000000130 | ├┼┼┼┼┼┼┼┼┼┼┼○▒▒ | 0b000000000000000 |
| 26 | 000000000000200 | ├┼┼┼┼┼┼┼┼┼┼┼●┼┤ | 0b000000000000000 |
| 27 | 000000000000201 | ├┼┼┼┼┼┼┼┼┼┼┼●┼○ | 0b000000000000000 |
| 28 | 000000000000202 | ├┼┼┼┼┼┼┼┼┼┼┼●┼● | 0b000000000000000 |
| 29 | 000000000000203 | ├┼┼┼┼┼┼┼┼┼┼┼●┤▒ | 0b000000000000000 |
| 30 | 000000000000210 | ├┼┼┼┼┼┼┼┼┼┼┼●○┤ | 0b000000000000000 |
| 31 | 000000000000211 | ├┼┼┼┼┼┼┼┼┼┼┼●○○ | 0b000000000000000 |
| 32 | 000000000000212 | ├┼┼┼┼┼┼┼┼┼┼┼●○● | 0b000000000000000 |
| 33 | 000000000000213 | ├┼┼┼┼┼┼┼┼┼┼┼●○▒ | 0b000000000000000 |
| 34 | 000000000000220 | ├┼┼┼┼┼┼┼┼┼┼┼●●┤ | 0b000000000000000 |
| 35 | 000000000000221 | ├┼┼┼┼┼┼┼┼┼┼┼●●○ | 0b000000000000000 |
| 36 | 000000000000222 | ├┼┼┼┼┼┼┼┼┼┼┼●●● | 0b000000000000000 |
| 37 | 000000000000223 | ├┼┼┼┼┼┼┼┼┼┼┼●●▒ | 0b000000000000000 |
| 38 | 000000000000230 | ├┼┼┼┼┼┼┼┼┼┼┼●▒▒ | 0b000000000000000 |
| 39 | 000000000000300 | ├┼┼┼┼┼┼┼┼┼┼┤▒▒▒ | 0b000000000000000 |
| 40 | 000000000001000 | ├┼┼┼┼┼┼┼┼┼┼○┼┼┤ | 0b000000000000000 |
| 41 | 000000000001001 | ├┼┼┼┼┼┼┼┼┼┼○┼┼○ | 0b000000000000000 |
| 42 | 000000000001002 | ├┼┼┼┼┼┼┼┼┼┼○┼┼● | 0b000000000000000 |
| 43 | 000000000001003 | ├┼┼┼┼┼┼┼┼┼┼○┼┤▒ | 0b000000000000000 |
| 44 | 000000000001010 | ├┼┼┼┼┼┼┼┼┼┼○┼○┤ | 0b000000000000000 |
| 45 | 000000000001011 | ├┼┼┼┼┼┼┼┼┼┼○┼○○ | 0b000000000000000 |
| … | … | … | … |
| 138 | 000000000010110 | ├┼┼┼┼┼┼┼┼┼○┼○○┤ | 0b000000000001000 |
| … | … | … | … |
| 174 | 000000000011100 | ├┼┼┼┼┼┼┼┼┼○○○┼┤ | 0b000000000100010 |
| 175 | 000000000011101 | ├┼┼┼┼┼┼┼┼┼○○○┼○ | 0b000000000000010 |
| 176 | 000000000011102 | ├┼┼┼┼┼┼┼┼┼○○○┼● | 0b000000000100000 |
| 177 | 000000000011102 | ├┼┼┼┼┼┼┼┼┼○○○┤▒ | 0b000000000100000 |
| … | … | … | … |
| 21523354 | 222223000000000 | ●●●●●▒▒▒▒▒▒▒▒▒▒ | 0b000000000000000 |
| 21523355 | 222230000000000 | ●●●●▒▒▒▒▒▒▒▒▒▒▒ | 0b000000000000000 |
| 21523356 | 222300000000000 | ●●●▒▒▒▒▒▒▒▒▒▒▒▒ | 0b000000000000000 |
| 21523357 | 223000000000000 | ●●▒▒▒▒▒▒▒▒▒▒▒▒▒ | 0b000000000000000 |
| 21523358 | 230000000000000 | ●▒▒▒▒▒▒▒▒▒▒▒▒▒▒ | 0b000000000000000 |
该查找表共21523359项,紧密地编码了15格阳线和1到15格的所有阴线的各种格局,占41.1 MB内存。
使用方法稍加改动即可,将三进制位权重power3改为偏斜三进制位权重basesk3,该数列为OEIS A261547。
1 | constexpr int basesk3[16] { |
这样,我们就将相当繁琐的威胁点检查问题完全转化成了增量维护四个方向的棋盘表示,然后进行表项查找。41 MB左右的查找表如今能够完全存放在L3缓存当中,可想而知速度是极快的。
上述示例中,find_threat还可以进一步向量化,乃至整个操作的开销可压缩至约百余个时钟周期。
同样的思路可以用于获胜检查、评价函数等。如果你准备使用类AlphaGo的架构,不妨尝试将神经网络第一层改为沿阴阳四线进行的一维卷积,用此方法可以直接以查找取代第一层卷积运算。
本文是续在Cambricon-U之后的短小随想。
RIM体现了我们作为并不研究存内计算的研究者,对于存内计算的新认识。 提到存内计算概念,人们直觉上首先与冯·诺依曼瓶颈联系起来,并认为存内计算当然是解决瓶颈的不二法门。 除了业余的计算机科学爱好者,也不乏专业的研究者以这种口径撰写各类材料。
这是错误的。
在RIM的心路历程中,我们展示了过去的存内计算缘何不能支持计数,而计数(后继运算)乃是皮亚诺算术系统中的公理元素,是算术之基础。 我们通过取巧的办法,利用了一种体系结构领域学者并不熟悉的记数法,才首次实现了存内计算的计数功能。 但是这种取巧只能取一次,无情的自然不会允许我们第二次取巧成功,因为想要在电路中同时高效实现加法和乘法的记数法已被证明不存在*。
计算需要信息的流动,而存内计算要求它们呆在原地,这天然是矛盾的。 结合姚先生的结论,我们恐怕无法真正在一个存储阵列中高效地原位完成冯·诺伊曼机所需的各类计算。 让我预测的话,存内计算永远不会和冯·诺依曼瓶颈真正产生关系。
* Andrew C. Yao. 1981. The entropic limitations on VLSI computations (Extended Abstract). STOC’81. [DOI]
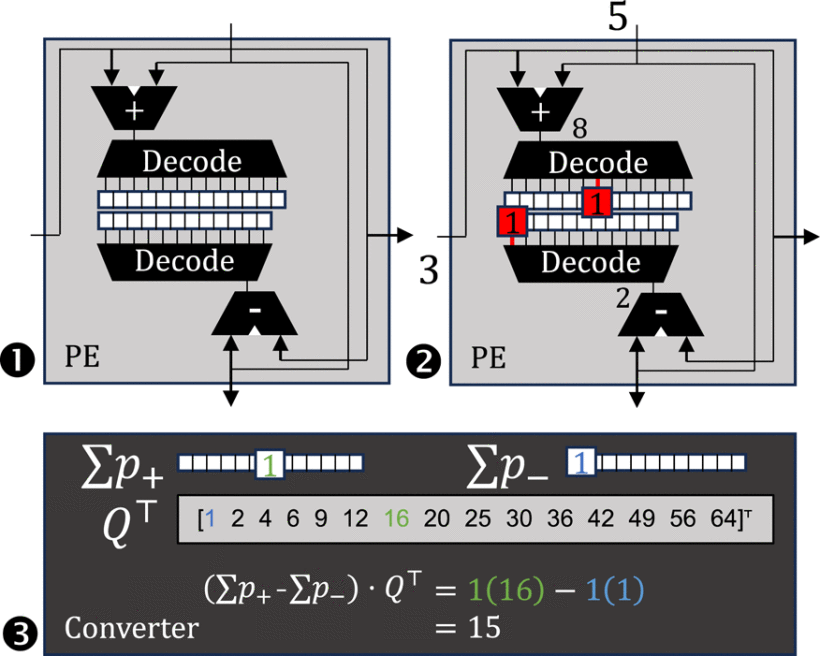
在MICRO 2023大会上,我们展示发明了一种新型存内计算器件“随机自增存储器(RIM)”,并将其应用于随机计算(一进制计算)架构中。
在学术界,存内计算是当前火热的研究领域,常被研究者寄予突破冯·诺依曼瓶颈、实现计算机体系结构大变革的美好期望。 但目前,存内计算这一概念的涵义却逐渐收敛于特指采用忆阻器、阻变存储器(ReRAM)等新材料、新器件完成矩阵计算这种特定计算功能。 在2023年,在我们这些原来并不研究存内计算的外行研究者看来,存内计算发展到了一个很奇怪的境地:已经发展出的存内计算设备能够很好地处理神经网络、功能类比大脑,却仍然无法做诸如计数、加法这样最基础的运算。 在Cambricon-Q的研究中,我们留下了一个遗憾:我们设计了NDPO在近存端完成权重更新,却无法做到真正的存内累加,因此被评阅人批评“只能称为近存计算,而非存内计算”。 由此,我们开始了对于如何在存储器内完成原位累加的思考。
我们很快意识到,如果采用二进制记数,加法是很难在存储器内原位完成的。 这是因为加法虽然简单,但存在进位传播:即使是对存内数值加1,也有可能导致所有比特全部发生翻转。 因此,在集成电路中制作计数器,需要一个完整的加法器来完成数值自增操作(后继运算),存储器内完整的数据必须全部被激活备用。
好在自增操作在平均情况下只会导致两个比特的翻转。我们需要找到一种记数法,控制最差情况下可能发生翻转的比特数量。因此我们引入了偏斜二进制记数法来代替二进制。偏斜记数法最初提出时是用于数据结构设计,例如用于Brodal堆,控制堆发生归并时的最差情况时间复杂度,而这与控制加法的进位传播十分类似。
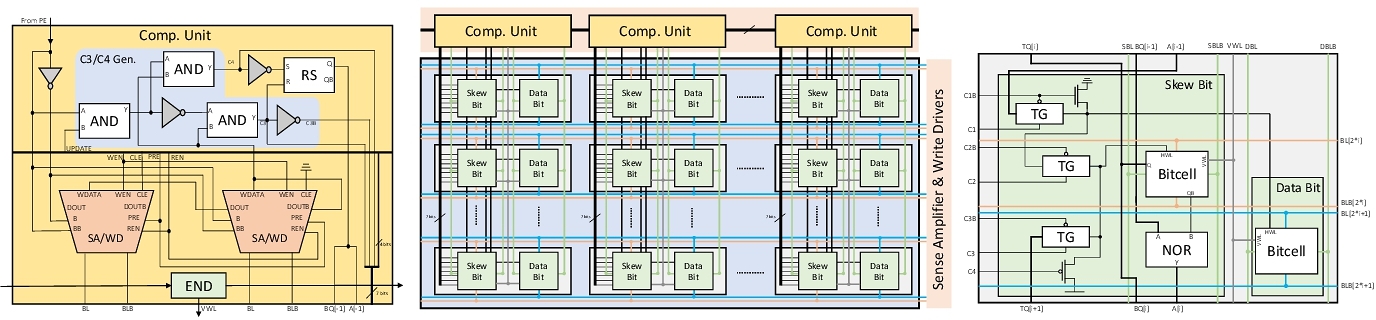
我们使用CMOS上的SRAM技术作为基础来设计RIM。我们将存储的数值(以偏斜记数法记录)按列向存储,并为每一列额外提供一列SRAM单元格用来存储每一数位的偏斜状态(即偏斜数中的数位“2”)。偏斜数的自增操作规则如下:

虽然每一个数中的“2”所处的行可能不同(偏斜记数规则中要求一个偏斜数中最多只能有一位为“2”),导致要操作的单元格随机分布在存储器阵列里,不能按以往SRAM的行选方式来激活;但我们可以使用上一位的偏斜状态来激活本位和下一位的对应单元,实现在同一操作周期中激活出位于不同行的单元格!
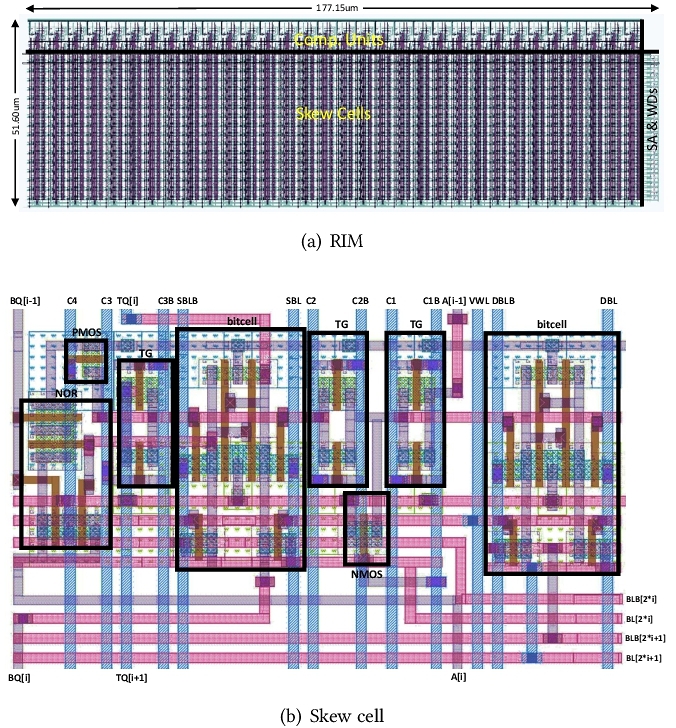
最终,我们实现了24T的RIM单元格——没有使用新材料,而是完全由CMOS技术构建。RIM能够实现对所存数据的随机自增:在同一操作周期里,RIM所存储的一些数据可以按需自增,而其他数据可以保持不变。

我们将RIM应用于随机计算(一进制计算)中。 随机计算的一大痛点在于一进制数与二进制数之间的转化开销——二进制数转一进制数需要随机数发生器,一进制数转二进制数需要计数器。因为一进制数数位太长(可达上千比特),使用一进制数完成计算后,中间结果如需暂存,必须转换回二进制,使计数操作所消耗的能量甚至能达到整个计算架构的78%。 我们使用RIM替换了uSystolic中的计数器,构建了Cambricon-U架构,显著降低了计数操作的能耗。 这项工作解决了基于随机计算的深度学习处理器的一项关键痛点,使相关技术有望更快应用。
整个五月都在帮人改文章当中度过。
在我们的教育体系里,学生写研究生学位论文之前,从来没有人教过他们怎么写。这导致了很多问题:学生不会写,老师改得痛苦;千叮咛万嘱咐,改了一版又一版,一两个月过去了,答辩完还是被逮捕。大部分文章出现的问题都是共性的,然而却需要我们每个人手把手地教,非常费时费力,效果也不好。我总结一部分共性问题,供有需要的同学自查自纠。
为了方便完全不懂写作的同学也能意识到问题,我给出的都是非常表面、浅显、刻板的现象,全部是写个寥寥几行的脚本就能计算出来的指标。请注意:不出现这些现象不意味着论文就能过关,出现了也不意味着一定就不是优秀的论文了。希望能引起读者自己的思考,考虑一下为什么问题论文浮现出的表面现象大多是这样的。
“极”当然可以作为极限的意思在科学术语当中使用,但更多时候,论文里用“极”、“很”、“非常”等等词汇只是为了表达强调。 在语言中,这些词汇的作用是输出情绪,属于主观成分,而对客观地描绘事物几乎没有帮助。 论文作为科学的文字载体,必须保持客观。 写下这些主观描述程度的词汇的时候,同学们需要引起特别警惕,要着重检查自己是否已经脱离了保持客观这一基本要求。 一般同学一旦犯了这样的错误,会连续犯一大串,给评审专家留下的阅读体验可想而知会是多么的不专业。
类似地,建议同学检查论文里是否出现了其他形式的主观评判,例如“取得了广泛应用”“做出了突出贡献”,或者反过来的“效果有限”之类的词句。 这些是只有评审专家才能讲的,评审是要求专家发表主观意见的过程。论文作者要论述客观规律,没有资格讲自己;除非给出明确而客观的依据,论文作者也没有资格讲别人。
解决方法是提供客观的依据。 比如“效率极高”可以改成“在(某项测试)中效率达到了98.5%”;“应用广泛”可以改成“在情感分析[17]、对话系统[18]、摘要生成[19]等领域得到应用”。
你肯定懒得弄参考文献,从DBLP、ACM DL或者出版商网站上复制一份BiBTeX,粘在一起就用了,最后排版出来的参考文献部分长什么样完全交给不知道从哪拷来的bst文件控制。 最后做出来的效果就是,参考文献项目参差不齐:有的缺项,有的又多出很多意义不明的项目出来。所以,我说粗略数一下每一条参考文献里出现了多少个项目域,算算方差就能体现出论文质量来。 参考文献里的问题可真是五花八门了,花多少时间去整理都整不完,所以最能体现作者对论文的上心程度,区分度很高。 同一个会议名称,有的只写会议全称,有的前面加了主办方,有的后面加了缩写,有的用年份区分,有的用届区分; 明明有DOI,有些参考文献后面又给了个arXiv的URL;标题里大小写混乱,有时还连续出现NVIDIA的一百种写法。 所以写论文到底用没用心,用了多少时间打磨,看一眼参考文献就露馅了。学位会上评定论文的时候时间紧张,一定是先从这个弱点开始查起,想蒙混过关是不可能的。
解决方法只有下功夫自己捋一遍,需要不怕麻烦、多花时间。出版商网站上给出的项目只能参考,BiBTeX只是个排版工具,里面要填什么内容最后还是要靠作者来控制。
汉语里是没有这个符号的,英语里也没有,我所知的人类语言都不用这个符号。 只有代码写多了,把论文当成代码文档来写,论文里夹带了代码碎片才会出现这个符号。 这一条定律是刻画得最准确的,几乎没有反例。
论文写作的目的是向其他人传播你的学术观点。要高效地向其他人传递知识,论文必须先对知识进行抽象和提炼。 总不能抛出一堆原始材料去要求读者自行理解,不然作者的贡献在哪里? 抽象的过程就是抛弃掉与叙事无关的实现细节(代码就是其中最恼人的细节),保留令人眼前一亮的思路和诀窍。 因此,任何一篇好的文章里都不会出现代码碎片,好的作者也压根不会有想以含下划线的名字命名任何概念的想法。
解决方法是补完知识抽象和为抽象概念命名的过程。代码、数据、定理推演如要保留,也扔到附录里去,作为补充材料,不要把他们算作文章里的一份子。
学位论文要求是用汉语写作的,然而差劲的论文特别喜欢在汉语语境里夹杂其他东西。 上一条批判的是夹杂代码碎片(讲不好人话),这一条要批判夹杂所有非汉语的内容(讲不好中国话)。 AlphaGo(阿尔法围棋)不用汉语情有可原,Model-based RL(基于模型的强化学习)就没道理夹生了吧? 今年有两个同学写出这样的话:“降低cache的miss率”,整篇论文变成了夹生饭。 研究生准备毕业了,却连母语都讲不好,显现出了论文的低质量。 论文里用到英文命名的概念一时不知道如何用汉语表达很正常。如果这个概念很重要,你当然应该花时间去寻找它的公允译名;如果是新概念就下点心思起一个专业、准确、可辨识的名字;如果你懒得寻找名字懒得起名,说明这些根本就是连自己也不看重的凑篇幅的废话罢了。
建议发现自己有类似习惯的同学,写作的时候给自己立个规矩:文章里每用到一个汉字、阿拉伯数字和汉语标点符号之外的字符,给红十字会捐一元钱。要让自己往汉语论文里写西文的时候,下意识地产生肉疼的感觉。西文不是不能写,至少不能滥用。
爱因斯坦是这样写公式的:
假如相对论是我们的同学创立的,这个公式可能就变成这样了:
至少也要把文字写在文字模式下吧!用\text或者\mathrm包裹起来,不要变成
不说啥了,体会一下大师的差距吧。为什么别人做出的工作是传世经典,我们的还在挣扎通过学位会审核呢? 做工作的时候没有下心思去简化表述,文字也充满赘语,图片也纷繁复杂,竟然连小小的公式符号都缩短不下去。 复杂度越高,学术美感就越差。
当你凑不够篇幅的时候,堆砌图表总比绞尽脑汁多写点文字来得更快一些。 于是同学们写文章的时候,一写到了实验这一部分,拿起程序调优器(profiler)来一顿截图——连续七八张插图,满屏幕色块花花绿绿,感觉论文的分量霎时间就充足、饱满了起来。 结果评审专家拿到论文一筹莫展,这都是啥?啥?啥? 一堆小色块堆砌在那里,与之配套的文字说明几乎没有,想参透背后的逻辑可比智商测试题有挑战得多啦! 除了作者也就只有鬼能知道这图到底是什么意思了(实际上很可能连作者自己也不知道,只有鬼才知道)。 你的论文大体水准还行的时候,为了避免场面太尴尬,看破不说破,专家也就睁一只眼、闭一只眼,权当你这一段没写了。 论文水准若是不行,你堆砌的这些谜一样的配图怕是会成为让专家丧失信心的最后一根稻草。
我这个指标的计算方法如果算出较高的值,至少说明文章中某一部分图、文搭配的比例出了问题,很可能提示了存在有配图未在文字中予以说明、引用论证的情况。 文章的主体是文字,图、表只是方便直观理解文章内容的辅助工具。 使用图、表首先应注意它的辅助说明性质,是对文字的补充。不能本末倒置,绝不应该出现连续的图、表罗列。 其次,还要注意图、表的直观性。 它们要表达的意义应当明确,能够自述清楚(让专家看第一眼就能理解这份图表想要表达的意图); 图、表较为复杂的时候,应当突出重点,引导读者的注意力。 或者,为复杂的图、表搭配详细的阅图(阅表)指引文字。
承接上一条。写论文的时候,建议抠掉键盘上的PrintScreen——恶魔之键。 在这个键的诱惑下,同学们总是懒得画图,从VCS、NSight、VS Code甚至命令提示符终端之类的软件用户界面上直接截取一部分下来,就作为配图插入论文中了。 结果是几乎逃不脱字号过大或过小、字体不匹配、作图风格混乱、说明文字缺失、重点不突出、简单罗列堆砌原始材料等一系列问题。 虽然其中的问题不一定十分致命,但是给人的观感一定特别差。不论图本身的意义明确了没有,首先就给人留下一个懒散的印象。
从IDE截图的,截下来的内容肯定是代码吧!参见第三、第四定律。 而截取终端里程序执行打印出的调试日志作为配图的同学是最恶劣的,还不如截代码呢。 代码好歹还有语法语义,执行日志是纯纯的占用篇幅、浪费纸墨的内容。
我评价论文的时候,首先会检查这个指标,因为很容易:找到最后一页出现相关工作的位置,手指卡住,合上论文,观察书脊前后两部分的比例。 整个过程可能只需要五秒,却能直观地戳穿同学拿相关工作凑篇幅的现象。 如果论文在这个检查下头重脚轻,注定逃不脱是一篇烂文章。因为要写好相关工作,比写好自己的工作还要难得多! 想象一下,答辩时专家们一边翻阅你的论文,一边努力分出一部分注意力来听你报告。 结果你却迟迟不进入自己的工作内容,浪费十几分钟在介绍一些或人尽皆知的、或陈词滥调的、或和本文工作几乎无关联的内容。 这次答辩的结果一定是非常糟糕的。
深入调研相关工作是需要大量精力和学术积累的。 首先需要对重要相关工作进行发现和筛选。 我们不去歧视科研机构和出版物,毕竟要评价具体工作的分量还是要坚持从客观的科学性评价出发。但引领性工作(在统计意义上)更经常由学术水平领先的机构发表在重要会议和刊物上。 而同学总是引用印度工程技术学院发表在Hindawi开放获取杂志上的文章,该领域开创性的重要工作却出现遗漏,足不足以说明对学科前沿还不够了解? 能够罗列出大量的重要相关工作,同时又避免夹带低水平相关工作,本身就是需要长期学术积累才能做成的一件难事。同学们在学术道路上初出茅庐,功底不够深厚是正常的,此时贪图在相关工作上凑篇幅写得太多太长,总是难免露怯。
其次,对遴选出的相关工作进行综述,本就是一份科学性很强的工作。如果做好,其学术价值不亚于学位论文中某一项研究点。 同学们没有那么多时间精力去梳理,或者还没有掌握进行综述的方法,大多数时候只能对相关工作简单罗列。 其中,掌握得比较好的同学大概能写成这样:
** 2 相关工作 **
2.1 某某甲的研究
某某甲很重要,有很多工作。
谁谁谁提出了啥啥啥,怎么怎么样。
谁谁谁提出了啥啥啥,怎么怎么样。
谁谁谁提出了啥啥啥,怎么怎么样。
但是他们都这样了。我们那样。
2.2 某某乙的研究
某某乙也很重要……
这样的写法至少在一串工作的罗列前后做到了有头有尾,也集中呼应了自己的工作,已经难能可贵了。要知道还有很多同学写不成这个水平,只有其中罗列的部分,有甚者一列就是二三十条。 评审专家若成心想刁难作者让他下不了台,大可以一条一条地展开来问:“这项工作的诀窍是什么?”“这项和前面某一项工作的区别是什么?联系是什么?”“这项工作和你有什么关系?”二三十条问下来,人肯定是问傻了。 毕竟罗列这么多工作,有些工作在作者列上来之前可能根本连文章都没打开过,直接从谷歌学术上复制个BiBTeX项进来就草草了事了。 我列举的三个方面问题对应着相关工作的三个必备要素:关键科学思想或发现、分类学和主题相关性。 一个好的综述,应该做到对每一项相关工作的诀窍能够一句话解释清楚;相关工作从不同维度梳理成多个类别,分类合理、界限清楚;每一类工作之间逻辑关系明确、叙事线索清楚,与文章主题紧密相关。 这是非要作者具有很强的科学抽象、语言凝练能力不可的,需要一段反复的推敲和辩证过程才能成文。
学位论文的第一章只要把大约三个研究点归纳到一起,就已经难倒多数同学了。 所以我特别建议同学们,除非有特别的理解,不要轻易在第二章集中介绍相关工作。这样写特别考验写作能力。建议在各个研究点的论述过程中,在真正引用到相关工作的具体位置上,进行针对性的介绍。 否则同学未经科学写作训练,很容易将集中的相关工作章节写成意义不明的一段凑篇幅的内容。 既然是凑篇幅的内容,文章的正文工作越单薄,为了显得篇幅充足,这部分内容凑得自然也就越多。 这段内容占比越长,通常意味着论文质量越差,也就不难理解了。
另一个凑篇幅的重灾区在于实验部分。 毕竟相比于写文章的痛苦,动动手做实验显得舒适多了。 多设计几个无关紧要的指标,画个柱状图做对比,matplotlib脚本都是现成可复用的; 或者数据列成表格,一行可能都放不下,一下子又多占了许多页面。 还有相当多的同学,想凑三个研究点出来却凑不满,就把实验提取出来堆砌在一起,作为论文的第五章、第三个研究点来写。 作为单独的一章,连续的实验部分至少也是十几、二十多页打底,才不显得单薄。 实验罗列到一起,与相关工作罗列到一起,造成的危害是一样严重的。实验原本用来验证研究内容,现在一些研究内容失去了实验支持,而一堆缺乏组织逻辑的实验数据又堆砌到了一起,再一次构成了意义不明的凑篇幅内容。 第九定律提出的是特别为检查这一常见做法而设计的指标。
这种心态应该归结于两点。
其一,经验主义认识的盛行:只将实验看作科学研究的一等公民,从而忽略了建立和传播科学抽象的价值。 作为物理学前沿研究的重要基础设施,北京正负电子对撞机已经产生了超过10PB的实验数据。 很多重要科学发现最初都来源于这些原始数据。 将这些数据印刷编纂成册,一定会成为科学价值极高的著作,让物理学家人手一套吧? 不然。 因为人类用符号语言传递信息的带宽只有约39bps,100年的寿命中一个人能接受上限为15GB的符号数据。 没有人能在有生之年阅读完这些数据,更别提从中发现些什么了。 真正有科学价值的不是用图、表展示的数据,而是由数据作为印证的、抽象的科学思想。 实验在其中只起到了验证的作用,可以说不仅不是一等公民,甚至很多时候只是第二性的——科学研究中常常是先提出抽象的科学思想,才有特别设计的实验去验证真伪。
其二,将论文误解为一种工作量证明(PoW):实验是我攻读研究生期间写了代码干了活的直接证明材料,统统列上来作为我向老板、领导的工作汇报。 这样就是将自己在科学研究中的身份搞错了。 研究生不是力工。 科学探索不是出卖苦力,科学工作的一分耕耘大多数时候都不会有对应的一分收获产生(否则会被大家鄙称为“灌水”),对比工作量意义有限。 论文应该是创造性思想的载体,而不是对付雇主的打卡记录——前者将是富有科学价值的文献,后者除了付你工资的雇主之外再没有人会关心。 你的导师、评阅专家、答辩会成员、学位会成员,以及你论文未来潜在的读者,他们是不是你的雇主?他们关心的是什么,想看到的是什么? 写论文之前,一定要首先搞清这一点。
当然同学也会问:你说这些有什么用,谁不知道要写出科学价值,可我的工作就是平凡到凑不齐三个研究点,怎么办? 这里就得提醒还没临近毕业大限的同学,要有意识地避免落到这样的境地里来。 写学位论文一定要预先谋划,前期开展研究工作的时候就在同一领域内布局好三个研究点的大致内容,在导师的指导下开展一项工作,然后有针对性地开展另外一到两项的研究。 只要你完成了一项有价值的研究工作,就很容易延伸出三个研究点了,例如:以该工作本身作为第二点;查找该工作的缺陷,继续完善,是第三点;总结两项工作的思想,提出科学、凝练的形而上(模型、范式、原则、风格),是第一点。 其中形而上的部分完全可以在论文写作的过程中一同完成。
最差的情况下,也要保持实事求是。有几项工作就写几项,实验就原原本本地用来验证具体的工作内容,不要把实验提出来凑章节。
与之前九项不同,最后一项是一条建议性的内容,因此提出了唯一一项正相关的指标。 将文章写得富有条理、线索明确并非一件容易的事。 但是我们有一种快速改进的方法:强迫自己将文章每一处的线索明确地列出来,写在各级标题的下方。 我们拿相关工作来举例:
2 相关工作
这一章介绍某领域的重要相关工作,以便读者理解后文内容。从某方面来看,某领域的研究工作大致可以分为甲、乙、丙;从某某方面来看,这些工作又可以按照某因素分为子、丑、寅、卯。本章将按某一顺序逐一简要介绍。笔者建议对某领域有兴趣的读者,可以阅读[18]作更深入的了解。
2.1 甲
解决某领域问题的一种较为直观的方式,是采用甲。甲具有A、B、C的特点,因此曾广泛应用于X [19]、Y [20]、Z [21]等。
谁[22]提出了甲子,怎么样。但是具有什么问题。
为了解决这一问题,谁[23]又提出了甲丑……
……
2.2 乙
虽然甲怎样怎样,但是如何如何。因此,自某年后,研究者开始转向乙。与甲不同的是,乙具有D、E、F的特点……
……
采用这种写法,读者每读到一处,都可以从标题下方的文字获得局部内容的阅读指引,阅读体验将会显著改善。 而更重要的是,有意识地遵循这种固定写法,可以强迫你对文章的叙述脉络进行整理。 只要能写得出来,就能保证文章是有结构、有条理、有逻辑的。 这种写法带来的特点是各级标题下都有一段导引性文字,不会有任何两个标题直接相邻。因此,我用标题间最小距离来刻画这一特点。
学位论文是同学们一生中独一无二的材料,论文代表了自己获取学位时的学术水平,在数据库中随时供人查阅参考。 虽然大家对我的博士论文给了比较高的评价,但我的论文里还是犯了以上一些错误; 学会将我的论文出版成册,再次校对的过程让我感到非常懊悔。 建议同学们还是应当将学位论文写作当作自己的一件人生大事去对待,用多少热情去仔细琢磨都不为过。
这一次我只是简单地从批判的角度来讨论论文写作,相对而言,建设性并不强。 希望同学们读到这些内容,经过思考后,能够体会到论文的基本要求,建立对论文基本的审美判断。 看到自己的不足之处是进步的基础;认识到论文写作需要遵循诸多限制、需要多下功夫,才能建立正确的心态。
上个月,我受教育处李丹老师邀请,面向毕业生做了一次学位论文写作和答辩心得报告,里面包含更多建设性的意见。 因为当时时间比较匆忙,其中很多内容还不完整或欠缺打磨。 学位论文写作是一项需要长远规划的重要工作,写好论文最重要的是要整理好自己的多项研究工作,而这些研究工作又需要从开展研究之初就进行谨慎的选题和谋划。 因此我认为类似的报告不应当放在五月、面向毕业生开展,而更应当放在九月、面向入学新生开展。 我计划争取在九月前将内容补充完整,然后再进行分享。